Global Ai Training Dataset Market
Tamanho do mercado em biliões de dólares
CAGR :
% 
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 –2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
Segmentação do mercado global de conjuntos de dados de treinamento de IA, por software (ferramentas de coleta de dados, software de anotação de dados e conjuntos de dados prontos para uso), tipo (imagem/vídeo, áudio e texto), vertical (TI, automotivo, governo, saúde, BFSI e varejo e comércio eletrônico) - Tendências do setor e previsão até 2032
Tamanho do mercado de conjuntos de dados de treinamento de IA
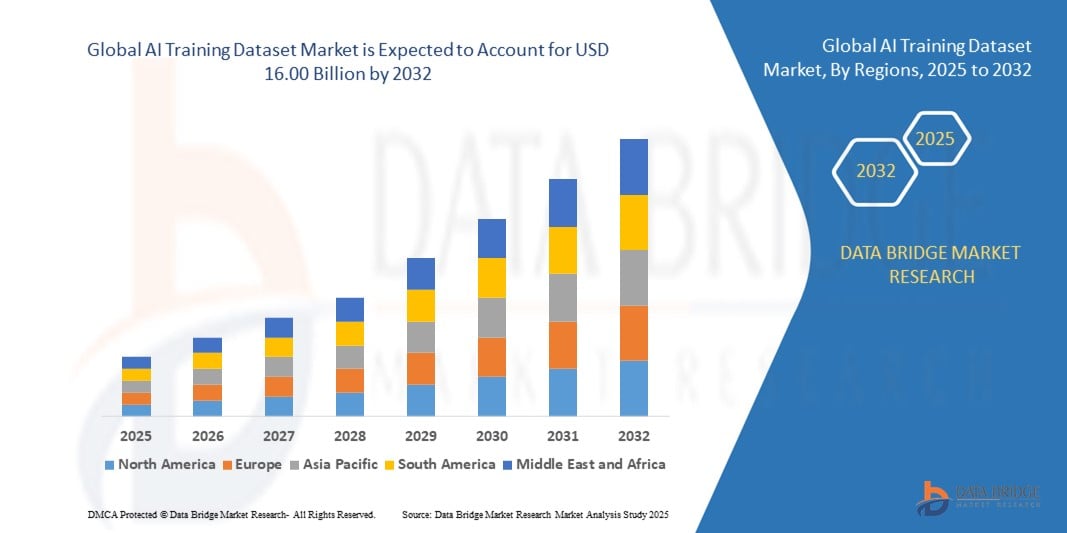
- O tamanho do mercado global de conjuntos de dados de treinamento de IA foi avaliado em US$ 2,72 bilhões em 2024 e deve atingir US$ 16,00 bilhões até 2032 , com um CAGR de 24,80% durante o período previsto.
- O crescimento do mercado é amplamente impulsionado pela crescente adoção de tecnologias de inteligência artificial e aprendizado de máquina em setores como saúde, automotivo, varejo e BFSI, o que levou a um aumento acentuado na demanda por conjuntos de dados de treinamento anotados de alta qualidade para melhorar a precisão e o desempenho do modelo.
- Além disso, a proliferação de aplicações intensivas em dados — que vão desde a visão computacional e reconhecimento de fala até a PNL e análise preditiva — está levando as organizações a investir em conjuntos de dados escaláveis e específicos de domínio, impulsionando significativamente a expansão da indústria de conjuntos de dados de treinamento de IA.
Análise de mercado de conjuntos de dados de treinamento de IA
- Conjuntos de dados de treinamento de IA consistem em dados estruturados ou anotados usados para treinar modelos de aprendizado de máquina em ambientes de aprendizado supervisionados e semissupervisionados. Esses conjuntos de dados podem incluir imagens, áudio, vídeo, texto ou entradas multimodais e são essenciais para ensinar sistemas de IA a reconhecer padrões, fazer previsões e automatizar decisões com intervenção humana mínima.
- O rápido crescimento no desenvolvimento de IA está gerando uma demanda massiva por dados de treinamento, especialmente em setores que desenvolvem sistemas inteligentes para diagnóstico, detecção de fraudes, navegação autônoma e mecanismos de recomendação. Como resultado, o mercado está apresentando um crescimento robusto, apoiado por crescentes investimentos em serviços de anotação de dados, plataformas de dados sintéticos e ecossistemas de marketplace de IA.
- A América do Norte dominou o mercado de conjuntos de dados de treinamento de IA com uma participação de 36,3% em 2024, devido ao forte ecossistema de IA da região, aos amplos investimentos em P&D e à presença de grandes empresas de tecnologia e startups de IA.
- Espera-se que a Ásia-Pacífico seja a região de crescimento mais rápido no mercado de conjuntos de dados de treinamento de IA durante o período previsto devido à rápida transformação digital, à expansão dos casos de uso de IA e ao aumento do apoio governamental ao desenvolvimento de IA em economias como China, Japão, Índia e Coreia do Sul.
- O segmento de imagem/vídeo dominou o mercado, com uma participação de mercado de 41,5% em 2024, devido à explosão de aplicações de visão computacional, como autenticação facial, direção autônoma, diagnóstico médico e vigilância no varejo. Esses modelos exigem grandes volumes de imagens e quadros de vídeo anotados para identificar, classificar e rastrear objetos com alta precisão. O rápido crescimento de dispositivos de ponta e visão embarcada em drones, robótica e infraestrutura inteligente impulsiona ainda mais a demanda por conjuntos de dados visuais. As organizações também estão utilizando cada vez mais conjuntos de dados sintéticos de imagem e vídeo para complementar dados do mundo real, melhorando a robustez do modelo em diversas condições ambientais.
Escopo do Relatório e Segmentação do Mercado de Conjuntos de Dados de Treinamento de IA
|
Atributos |
Principais insights de mercado do conjunto de dados de treinamento de IA |
|
Segmentos abrangidos |
|
|
Países abrangidos |
América do Norte
Europa
Ásia-Pacífico
Oriente Médio e África
Ámérica do Sul
|
|
Principais participantes do mercado |
|
|
Oportunidades de mercado |
|
|
Conjuntos de informações de dados de valor agregado |
Além de insights de mercado, como valor de mercado, taxa de crescimento, segmentos de mercado, cobertura geográfica, participantes do mercado e cenário de mercado, o relatório de mercado selecionado pela equipe de pesquisa de mercado da Data Bridge inclui análise aprofundada de especialistas, análise de importação/exportação, análise de preços, análise de consumo de produção e análise pilão. |
Tendências de mercado de conjuntos de dados de treinamento de IA
Adoção crescente de dados de treinamento sintéticos
- O mercado de conjuntos de dados de treinamento de IA está evoluindo rapidamente à medida que os dados sintéticos ganham força como uma alternativa escalável e compatível com a privacidade à anotação de dados tradicional, superando as limitações relacionadas à escassez de dados, viés e exposição de informações confidenciais.
- Por exemplo, empresas como a NVIDIA e a Mostly AI são especializadas em plataformas de geração de dados sintéticos que permitem a criação de conjuntos de dados rotulados de alta qualidade para treinamento de visão computacional, processamento de linguagem natural e sistemas autônomos em setores como saúde, automotivo e finanças.
- A flexibilidade dos dados sintéticos permite a criação de cenários de eventos raros ou conjuntos de dados balanceados, mitigando vieses e aprimorando a generalização do modelo
- O aumento do escrutínio regulatório em torno do uso de dados pessoais incentiva a adoção de conjuntos de dados sintéticos que preservam a privacidade, mantendo ao mesmo tempo a utilidade analítica.
- Os avanços nas redes adversárias generativas (GANs) e nas tecnologias de simulação facilitam amostras de dados sintéticos realistas e diversas, acelerando os ciclos de desenvolvimento da IA
- Os conjuntos de dados sintéticos estão cada vez mais integrados com conjuntos de dados do mundo real para otimizar a eficácia do treinamento e reduzir os riscos de overfitting em modelos de aprendizado de máquina
Dinâmica de mercado de conjuntos de dados de treinamento de IA
Motorista
Crescente demanda por conjuntos de dados multilíngues e específicos de domínio em todos os setores
- Com a adoção da IA se expandindo em setores como saúde, automotivo, varejo e telecomunicações, a necessidade de conjuntos de dados multilíngues e específicos de domínio meticulosamente selecionados está crescendo para oferecer suporte ao treinamento de modelos específicos de idioma, contexto e tarefa.
- Por exemplo, a Appen e a Lionbridge fornecem conjuntos de dados anotados abrangentes em vários idiomas e domínios especializados, ajudando as empresas a desenvolver aplicações de IA robustas em atendimento ao cliente, diagnósticos médicos e veículos autônomos adaptados aos mercados locais e ambientes regulatórios.
- O aumento da localização e personalização de produtos de IA exige dados de treinamento de alta qualidade e contextualmente relevantes para melhorar a precisão e a satisfação do usuário. A conformidade com as regulamentações do setor, especialmente em saúde e finanças, exige curadoria de dados com reconhecimento de domínio, garantindo que os modelos de IA atendam aos padrões legais e éticos.
- A crescente popularidade da IA conversacional, da análise de sentimentos e das ferramentas de tradução de idiomas estimula a demanda por conjuntos de dados diversificados de texto, fala e imagem em vários idiomas e dialetos
- Parcerias estratégicas entre desenvolvedores de IA e empresas de anotação de dados facilitam a criação sob demanda de conjuntos de dados especializados, acelerando o tempo de lançamento de soluções de IA no mercado.
Restrição/Desafio
Altos custos e tempo intensivo de anotação manual de dados
- A anotação manual continua sendo um gargalo crítico devido à sua natureza trabalhosa, propensa a erros e cara, muitas vezes exigindo especialistas de domínio e longos ciclos de validação que retardam o treinamento e a implantação do modelo de IA
- Por exemplo, as empresas que dependem da rotulagem manual para conjuntos de dados complexos de imagens ou vídeos, como desenvolvedores de direção autônoma ou empresas de imagens médicas, enfrentam altos custos operacionais e desafios de escalabilidade, apesar dos rigorosos requisitos de qualidade.
- A dificuldade em recrutar e treinar anotadores qualificados com experiência no domínio agrava os atrasos e a variabilidade na qualidade dos dados entre os projetos
- Inconsistências nas anotações e problemas de controle de qualidade exigem retrabalho e processos de revisão em camadas, o que aumenta o tempo e as despesas. O aumento do tamanho dos conjuntos de dados, impulsionado pelos avanços na complexidade dos modelos de IA, intensifica a demanda por anotações, sobrecarregando ainda mais os recursos humanos e os orçamentos.
- O setor está explorando ativamente ferramentas de anotação semiautomatizadas e assistidas por IA para reduzir custos e tempo de resposta, mas a ampla adoção ainda é desafiada pela confiabilidade do modelo e pelas complexidades de integração
Escopo de mercado de conjuntos de dados de treinamento de IA
O mercado é segmentado com base em software, tipo e vertical.
- Por software
Com base em software, o mercado de conjuntos de dados de treinamento de IA é segmentado em Ferramentas de Coleta de Dados, Software de Anotação de Dados e Conjuntos de Dados Prontos para Uso. O segmento de Software de Anotação de Dados dominou o mercado em 2024, devido ao seu papel crítico na geração de dados rotulados de alta qualidade, essenciais para o treinamento de modelos de aprendizado supervisionado em setores como automotivo, saúde e varejo. Essas plataformas suportam uma variedade de tipos de dados, incluindo imagem, texto, áudio e vídeo, e frequentemente vêm equipadas com recursos de anotação assistida por IA que aceleram o processo de rotulagem. As empresas preferem essas ferramentas por sua capacidade de lidar com grandes conjuntos de dados, permitir a colaboração em tempo real entre equipes distribuídas e garantir consistência nas tarefas de rotulagem. Sua ampla integração com pipelines de aprendizado de máquina e compatibilidade com múltiplas estruturas de treinamento de modelos reforçam ainda mais seu domínio.
Prevê-se que o segmento de Conjuntos de Dados Prontos para Uso (PDD) apresente o CAGR mais rápido entre 2025 e 2032, impulsionado pela crescente demanda de empresas que buscam reduzir o tempo de lançamento de suas soluções de IA no mercado. Esses conjuntos de dados pré-rotulados são selecionados para domínios específicos, como reconhecimento facial, detecção de fraudes ou imagens médicas, permitindo que as equipes de IA pulem a demorada fase de coleta de dados. Startups e pequenas empresas, em particular, se beneficiam de sua acessibilidade, velocidade e garantia de qualidade. Além disso, à medida que a generalização de modelos se torna um foco importante, conjuntos de dados prontos para uso são cada vez mais procurados para fins de benchmarking e pré-treinamento, especialmente em aprendizagem por transferência e desenvolvimento de modelos básicos.
- Por tipo
Com base no tipo, o mercado de conjuntos de dados de treinamento de IA é segmentado em Imagem/Vídeo, Áudio e Texto. O segmento de Imagem/Vídeo representou a maior fatia, 41,5%, em 2024, devido à explosão em aplicações de visão computacional, como autenticação facial, direção autônoma, diagnóstico médico e vigilância no varejo. Esses modelos exigem grandes volumes de imagens e quadros de vídeo anotados para identificar, classificar e rastrear objetos com alta precisão. O rápido crescimento de dispositivos de ponta e visão embarcada em drones, robótica e infraestrutura inteligente alimenta ainda mais a demanda por conjuntos de dados visuais. As organizações também estão cada vez mais utilizando conjuntos de dados de imagem e vídeo sintéticos para complementar dados do mundo real, melhorando a robustez do modelo em condições ambientais variadas.
Espera-se que o segmento de áudio registre a maior taxa de crescimento entre 2025 e 2032, impulsionado pelo amplo uso de IA em aplicativos de voz, incluindo assistentes virtuais, automação de call centers e serviços de transcrição multilíngue. Conjuntos de dados de áudio anotados com contextos de fala, eventos acústicos e ruído de fundo são essenciais para melhorar a precisão em tarefas de reconhecimento de fala e classificação de sons. O crescimento é ainda mais acelerado pelo aumento da P&D em IA de voz com reconhecimento emocional e tecnologias de acessibilidade para deficientes visuais. Com a crescente demanda por dados de voz em idiomas e dialetos regionais, os provedores de conjuntos de dados estão expandindo suas ofertas para oferecer suporte a perfis linguísticos e acústicos diversificados.
- Por Vertical
Com base na vertical, o mercado de conjuntos de dados de treinamento de IA é segmentado em TI, Automotivo, Governo, Saúde, BFSI e Varejo e E-commerce. O segmento de TI liderou o mercado em 2024, com empresas de tecnologia e provedores de serviços em nuvem investindo pesadamente em treinamento de IA para segurança cibernética, automação e aprimoramento da experiência do cliente. Essas organizações frequentemente desenvolvem conjuntos de dados internos ou adquirem grandes volumes de dados estruturados e não estruturados para dar suporte ao desenvolvimento de modelos, testes e aprendizado contínuo. O ritmo acelerado da inovação de software e da integração de IA em plataformas e serviços alimenta a demanda contínua por conjuntos de dados diversos e específicos para tarefas. Além disso, o acesso do setor de TI a ferramentas avançadas para rotulagem e processamento de dados permite que ele mantenha a liderança na utilização de conjuntos de dados.
O segmento de Saúde deverá testemunhar o crescimento mais rápido entre 2025 e 2032, impulsionado pela crescente adoção de IA em diagnósticos de doenças, análises de imagens, cirurgia robótica e sistemas de gestão de pacientes. O treinamento de modelos de IA neste setor requer conjuntos de dados grandes e bem selecionados, como exames de ressonância magnética, lâminas de patologia, dados genômicos e anotações clínicas, que devem obedecer a rigorosos padrões regulatórios e éticos. O aumento das colaborações público-privadas, como hospitais que firmam parcerias com empresas de IA para inovações baseadas em dados, está impulsionando a acessibilidade aos conjuntos de dados. Além disso, a busca por cuidados de saúde personalizados e preditivos está acelerando a demanda por dados longitudinais e multimodais de pacientes, tornando a saúde um setor vertical de alto crescimento para conjuntos de dados de treinamento de IA.
Análise regional do mercado de conjuntos de dados de treinamento de IA
- A América do Norte dominou o mercado de conjuntos de dados de treinamento de IA com a maior participação na receita de 36,3% em 2024, impulsionada pelo forte ecossistema de IA da região, amplos investimentos em P&D e a presença de grandes empresas de tecnologia e startups de IA
- As empresas na América do Norte estão investindo pesadamente no treinamento de modelos de IA para aplicações em saúde, finanças, direção autônoma e segurança cibernética, aumentando assim a demanda por conjuntos de dados de treinamento diversos e de alta qualidade.
- A região beneficia de infraestrutura de nuvem avançada, alta alfabetização digital e suporte regulatório favorável à inovação em IA, contribuindo para a aquisição e uso de conjuntos de dados em larga escala em todos os setores.
Visão do mercado de conjuntos de dados de treinamento de IA dos EUA
O mercado de conjuntos de dados de treinamento de IA dos EUA capturou a maior fatia da receita em 2024 na América do Norte, impulsionado pela forte adoção da IA em setores como saúde, automotivo e TI. O rápido desenvolvimento de aplicativos de aprendizado de máquina e processamento de linguagem natural continua a gerar demanda por dados rotulados, especialmente em formatos de imagem, fala e texto. Gigantes da tecnologia e startups estão aproveitando enormes volumes de dados de treinamento para desenvolver modelos proprietários de IA. Parcerias público-privadas, pesquisas apoiadas pelo governo e um setor acadêmico focado em inovação aceleram ainda mais o ecossistema de conjuntos de dados nos EUA.
Visão geral do mercado de conjuntos de dados de treinamento de IA na Europa
O mercado europeu de conjuntos de dados de treinamento em IA deverá crescer a uma CAGR substancial durante o período previsto, apoiado por rigorosas regulamentações de privacidade de dados e um foco crescente no desenvolvimento ético de IA. O crescimento da automação, dos serviços públicos baseados em IA e da manufatura inteligente está impulsionando a demanda por conjuntos de dados de alta qualidade em todo o continente. As empresas europeias estão enfatizando o uso de conjuntos de dados explicáveis e imparciais, alinhando-se à conformidade com o GDPR e aos padrões éticos. A adoção é notavelmente forte em setores como automotivo, saúde e governo, onde modelos de IA treinados com precisão são essenciais.
Visão geral do mercado de conjuntos de dados de treinamento de IA do Reino Unido
Espera-se que o mercado de conjuntos de dados de treinamento em IA do Reino Unido cresça a um CAGR significativo durante o período previsto, impulsionado por iniciativas nacionais que promovem a liderança em IA e a transformação digital. Com investimentos em centros de pesquisa em IA e a crescente demanda por automação inteligente em setores como BFSI e comércio eletrônico, a necessidade de conjuntos de dados confiáveis e pré-rotulados está aumentando. O vibrante ecossistema de startups do Reino Unido e a forte presença de provedores de IA como serviço fortalecem ainda mais o mercado. A ênfase na IA responsável e no uso justo de dados está incentivando o desenvolvimento de conjuntos de dados de alta qualidade e livres de vieses.
Visão geral do mercado de conjuntos de dados de treinamento de IA na Alemanha
O mercado alemão de conjuntos de dados de treinamento de IA deverá crescer de forma constante, impulsionado pela liderança do país em automação industrial, mobilidade inteligente e digitalização da saúde. As organizações alemãs estão adotando cada vez mais a IA em áreas como manutenção preditiva, veículos autônomos e diagnósticos médicos, todas as quais exigem conjuntos de dados precisos e específicos para cada domínio. O mercado se beneficia da colaboração entre instituições de pesquisa, empresas e iniciativas de IA apoiadas pelo governo. O foco da Alemanha em qualidade, proteção de dados e inovação atende à demanda por soluções de dados de treinamento seguras e escaláveis.
Visão do mercado de conjuntos de dados de treinamento de IA na Ásia-Pacífico
Espera-se que o mercado de conjuntos de dados de treinamento de IA na Ásia-Pacífico cresça com a CAGR mais rápida durante o período previsto de 2025 a 2032, impulsionado pela rápida transformação digital, pela expansão dos casos de uso de IA e pelo aumento do apoio governamental ao desenvolvimento de IA em economias como China, Japão, Índia e Coreia do Sul. A proliferação de dispositivos conectados à internet, populações multilíngues e mercados que priorizam dispositivos móveis está criando necessidades diversificadas de dados. Além disso, o papel da região Ásia-Pacífico como um centro global para talentos em IA e serviços de rotulagem de dados com boa relação custo-benefício acelera ainda mais a produção e o consumo de conjuntos de dados em todos os setores.
Visão geral do mercado de conjuntos de dados de treinamento de IA do Japão
O mercado japonês de conjuntos de dados de treinamento de IA está em constante crescimento, impulsionado pela ênfase do país em robótica, cidades inteligentes e sistemas de transporte inteligentes. A infraestrutura digital altamente avançada do Japão e o amplo uso de dispositivos conectados estão gerando grandes volumes de dados estruturados e não estruturados. As empresas estão utilizando ativamente a IA para lidar com a escassez de mão de obra e os desafios do envelhecimento populacional, especialmente nos setores de saúde e logística. A demanda por conjuntos de dados multimodais e específicos para cada idioma está aumentando à medida que a adoção da IA se expande para eletrônicos de consumo e serviços públicos.
Visão do mercado de conjuntos de dados de treinamento de IA da China
O mercado chinês de conjuntos de dados de treinamento de IA foi responsável pela maior fatia da receita na região Ásia-Pacífico em 2024, impulsionado pela estratégia de desenvolvimento de IA em primeiro lugar do país, pela digitalização em larga escala e pelo domínio em dispositivos inteligentes. A ampla implantação de sistemas de IA para reconhecimento facial, vigilância e comércio eletrônico gerou uma demanda massiva por conjuntos de dados rotulados. Programas apoiados pelo governo e a ascensão de empresas nacionais de IA criaram um ecossistema robusto para geração, anotação e distribuição de dados. As prósperas iniciativas chinesas de cidades inteligentes e veículos autônomos continuam a criar vastas oportunidades para provedores de conjuntos de dados.
Participação de mercado de conjuntos de dados de treinamento de IA
O setor de conjuntos de dados de treinamento de IA é liderado principalmente por empresas bem estabelecidas, incluindo:
- Escala AI (EUA)
- Appen (Austrália)
- Lionbridge (EUA)
- AWS (EUA)
- Sama (EUA)
- Clickworker (Reino Unido)
- Cogito Tech (EUA)
- CloudFactory (Reino Unido)
- TELUS International (Canadá)
- Innodata (EUA)
- iMerit (EUA)
- TransPerfect (EUA)
- Google (EUA)
- LXT (Canadá)
- IBM (EUA)
- Microsoft (EUA)
- NVIDIA (EUA)
Últimos desenvolvimentos no mercado global de conjuntos de dados de treinamento de IA
- Em setembro de 2024, a Innodata lançou seu Marketplace de Dados de IA, marcando um passo significativo para enfrentar os desafios de escalabilidade e acessibilidade de dados no treinamento de modelos de IA/ML. A plataforma oferece conjuntos de dados de documentos sintéticos, selecionados e sob demanda, que ajudam as equipes de ciência de dados a superar as limitações relacionadas ao volume, diversidade e privacidade dos dados. Ao simplificar o acesso a conjuntos de dados prontos para uso, espera-se que este marketplace acelere o desenvolvimento de modelos de IA e atenda à crescente demanda por dados de treinamento sintéticos e específicos de domínio em todos os setores.
- Em setembro de 2024, a SCALE AI anunciou um investimento de US$ 21 milhões em nove projetos de saúde baseados em IA em todo o Canadá, no âmbito da Estratégia Pan-Canadense de Inteligência Artificial. Esta iniciativa deverá impactar significativamente o mercado de conjuntos de dados de treinamento de IA na área da saúde, promovendo a colaboração entre hospitais e desenvolvedores de IA. O objetivo é aprimorar o atendimento ao paciente, reduzir o tempo de espera e otimizar as operações de saúde, aumentando assim a demanda por conjuntos de dados de alta qualidade, de origem ética e adaptados para aplicações clínicas, administrativas e de diagnóstico.
- Em agosto de 2024, a Lionbridge Technologies, Inc. lançou o Aurora AI Studio, uma plataforma dedicada focada em auxiliar empresas no treinamento de modelos de IA com conjuntos de dados de alta qualidade. Este lançamento atende à crescente necessidade de dados especializados e bem anotados para apoiar casos de uso avançados de IA. Ao alavancar a expertise global da Lionbridge em curadoria e anotação de dados, a plataforma fortalece o ecossistema comercial de IA e está pronta para influenciar a demanda por conjuntos de dados personalizados, multilíngues e específicos para cada setor em setores como finanças, varejo e telecomunicações.
- Em agosto de 2024, a Accenture, em parceria com o Google Cloud, acelerou a implantação de soluções de IA generativa por meio de seu Centro de Excelência em IA Generativa. Com 45% dos projetos em transição para produção, essa colaboração destaca a crescente operacionalização da IA em escala. Ela ressalta a necessidade urgente de conjuntos de dados de treinamento seguros, diversos e prontos para produção, que suportem modelos avançados de IA em todas as empresas. A iniciativa também integra a segurança cibernética, reforçando o papel do tratamento responsável de dados e de conjuntos de dados focados em privacidade na adoção de IA empresarial.
- Em julho de 2024, a Microsoft Research revelou o AgentInstruct, uma estrutura de fluxo de trabalho multiagente projetada para automatizar a geração de dados sintéticos de alta qualidade. Demonstrada por meio de melhorias em seu modelo Orca-3 em diversos benchmarks, essa estrutura minimiza a intervenção humana na rotulagem de dados, reduzindo custos e acelerando a criação de conjuntos de dados. Espera-se que o AgentInstruct remodele o mercado de conjuntos de dados de treinamento de IA, promovendo o uso de dados sintéticos para treinamento de modelos em larga escala, particularmente em IA generativa e modelos de base.
SKU-
Obtenha acesso online ao relatório sobre a primeira nuvem de inteligência de mercado do mundo
- Painel interativo de análise de dados
- Painel de análise da empresa para oportunidades de elevado potencial de crescimento
- Acesso de analista de pesquisa para personalização e customização. consultas
- Análise da concorrência com painel interativo
- Últimas notícias, atualizações e atualizações Análise de tendências
- Aproveite o poder da análise de benchmark para um rastreio abrangente da concorrência
Metodologia de Investigação
A recolha de dados e a análise do ano base são feitas através de módulos de recolha de dados com amostras grandes. A etapa inclui a obtenção de informações de mercado ou dados relacionados através de diversas fontes e estratégias. Inclui examinar e planear antecipadamente todos os dados adquiridos no passado. Da mesma forma, envolve o exame de inconsistências de informação observadas em diferentes fontes de informação. Os dados de mercado são analisados e estimados utilizando modelos estatísticos e coerentes de mercado. Além disso, a análise da quota de mercado e a análise das principais tendências são os principais fatores de sucesso no relatório de mercado. Para saber mais, solicite uma chamada de analista ou abra a sua consulta.
A principal metodologia de investigação utilizada pela equipa de investigação do DBMR é a triangulação de dados que envolve a mineração de dados, a análise do impacto das variáveis de dados no mercado e a validação primária (especialista do setor). Os modelos de dados incluem grelha de posicionamento de fornecedores, análise da linha de tempo do mercado, visão geral e guia de mercado, grelha de posicionamento da empresa, análise de patentes, análise de preços, análise da quota de mercado da empresa, normas de medição, análise global versus regional e de participação dos fornecedores. Para saber mais sobre a metodologia de investigação, faça uma consulta para falar com os nossos especialistas do setor.
Personalização disponível
A Data Bridge Market Research é líder em investigação formativa avançada. Orgulhamo-nos de servir os nossos clientes novos e existentes com dados e análises que correspondem e atendem aos seus objetivos. O relatório pode ser personalizado para incluir análise de tendências de preços de marcas-alvo, compreensão do mercado para países adicionais (solicite a lista de países), dados de resultados de ensaios clínicos, revisão de literatura, mercado remodelado e análise de base de produtos . A análise de mercado dos concorrentes-alvo pode ser analisada desde análises baseadas em tecnologia até estratégias de carteira de mercado. Podemos adicionar quantos concorrentes necessitar de dados no formato e estilo de dados que procura. A nossa equipa de analistas também pode fornecer dados em tabelas dinâmicas de ficheiros Excel em bruto (livro de factos) ou pode ajudá-lo a criar apresentações a partir dos conjuntos de dados disponíveis no relatório.