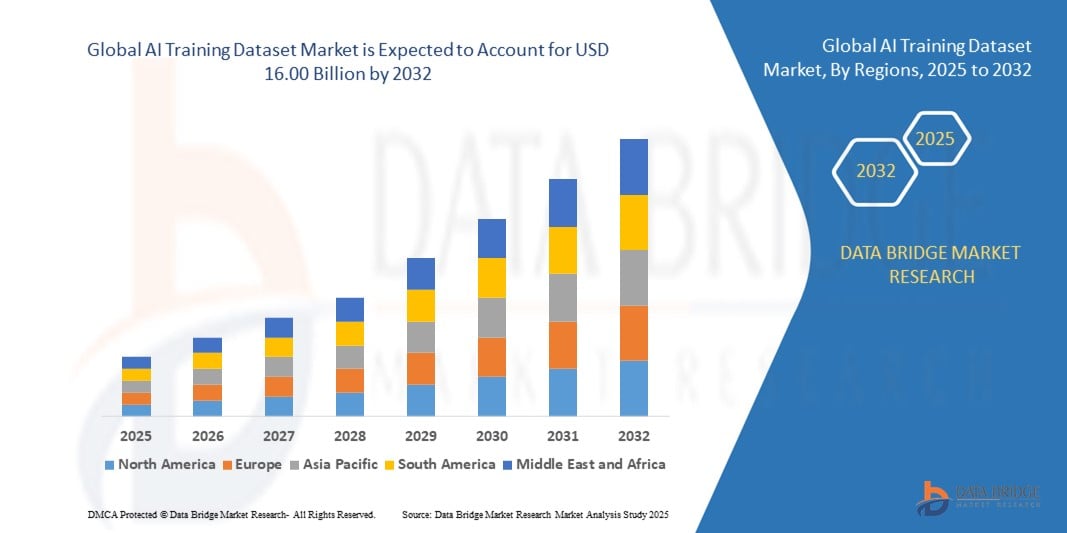
Global Ai Training Dataset Market
Market Size in USD Billion
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 - 2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
AI Training Dataset Market Size
- The global AI training dataset market size was valued at USD 2.72 billion in 2024 and is expected to reach USD 16.00 billion by 2032, at a CAGR of 24.80% during the forecast period
- The market growth is largely fueled by the increasing adoption of artificial intelligence and machine learning technologies across sectors such as healthcare, automotive, retail, and BFSI, which has led to a sharp rise in the demand for high-quality, annotated training datasets to improve model accuracy and performance
- Furthermore, the proliferation of data-intensive applications—ranging from computer vision and speech recognition to NLP and predictive analytics—is driving organizations to invest in scalable, domain-specific datasets, significantly boosting the expansion of the AI training dataset industry
AI Training Dataset Market Analysis
- AI training datasets consist of structured or annotated data used to train machine learning models in supervised and semi-supervised learning environments. These datasets may include images, audio, video, text, or multimodal inputs and are essential for teaching AI systems to recognize patterns, make predictions, and automate decisions with minimal human intervention
- The rapid surge in AI development is creating massive demand for training data, particularly in sectors developing intelligent systems for diagnostics, fraud detection, autonomous navigation, and recommendation engines. As a result, the market is experiencing robust growth, supported by rising investments in data annotation services, synthetic data platforms, and AI marketplace ecosystems
- North America dominated the AI training dataset market with a share of 36.3% in 2024, due to the region's strong AI ecosystem, extensive R&D investments, and the presence of major tech firms and AI startups
- Asia-Pacific is expected to be the fastest growing region in the AI training dataset market during the forecast period due to rapid digital transformation, expanding AI use cases, and increasing government support for AI development in economies such as China, Japan, India, and South Korea
- Image/video segment dominated the market with a market share of 41.5% in 2024, due to the explosion in computer vision applications such as facial authentication, autonomous driving, medical diagnostics, and retail surveillance. These models require vast volumes of annotated images and video frames to identify, classify, and track objects with high precision. The rapid growth of edge devices and embedded vision in drones, robotics, and smart infrastructure further fuels demand for visual datasets. Organizations are also increasingly leveraging synthetic image and video datasets to supplement real-world data, improving model robustness under varied environmental conditions
Report Scope and AI Training Dataset Market Segmentation
|
Attributes |
AI Training Dataset Key Market Insights |
|
Segments Covered |
|
|
Countries Covered |
North America
Europe
Asia-Pacific
Middle East and Africa
South America
|
|
Key Market Players |
|
|
Market Opportunities |
|
|
Value Added Data Infosets |
In addition to the market insights such as market value, growth rate, market segments, geographical coverage, market players, and market scenario, the market report curated by the Data Bridge Market Research team includes in-depth expert analysis, import/export analysis, pricing analysis, production consumption analysis, and pestle analysis. |
AI Training Dataset Market Trends
Growing Adoption of Synthetic Training Data
- The AI training dataset market is evolving rapidly as synthetic data gains traction as a scalable, privacy-compliant alternative to traditional data annotation, overcoming limitations related to data scarcity, bias, and sensitive information exposure
- For instance, companies such as NVIDIA and Mostly AI specialize in synthetic data generation platforms that enable creation of high-quality, labeled datasets for training computer vision, natural language processing, and autonomous systems in industries including healthcare, automotive, and finance
- Synthetic data's flexibility allows the creation of rare event scenarios or balanced datasets mitigating bias and enhancing model generalization
- Increasing regulatory scrutiny around personal data usage encourages adoption of synthetic datasets that preserve privacy while maintaining analytical utility
- Advances in generative adversarial networks (GANs) and simulation technologies facilitate realistic and diverse synthetic data samples, accelerating AI development cycles
- Synthetic datasets are increasingly integrated with real-world datasets to optimize training effectiveness and reduce overfitting risks in machine learning models
AI Training Dataset Market Dynamics
Driver
Rising Demand for Domain-Specific and Multilingual Datasets Across Industries
- With AI adoption expanding across verticals such as healthcare, automotive, retail, and telecommunications, the need for meticulously curated domain-specific and multilingual datasets is growing to support language, context, and task-specific model training
- For instance, Appen and Lionbridge provide extensive annotated datasets across languages and specialized domains helping enterprises develop robust AI applications in customer service, medical diagnostics, and autonomous vehicles tailored to local markets and regulatory environments
- Increasing AI product localization and personalization demands high-quality, contextually relevant training data to improve accuracy and user satisfaction. Industry regulation compliance, especially in health and finance, mandates domain-aware data curation ensuring AI models meet legal and ethical standards
- Rising popularity of conversational AI, sentiment analysis, and language translation tools spurs demand for diversified text, speech, and image datasets in multiple languages and dialects
- Strategic partnerships between AI developers and data annotation companies facilitate on-demand creation of specialized datasets driving faster time-to-market for AI solutions
Restraint/Challenge
High Costs and Time Intensiveness of Manual Data Annotation
- Manual annotation remains a critical bottleneck due to its labor-intensive, error-prone, and expensive nature, often requiring domain experts and lengthy validation cycles that slow down AI model training and deployment
- For instance, enterprises relying on manual labeling for complex image or video datasets, such as autonomous driving developers or medical imaging companies, face high operational costs and scalability challenges despite stringent quality requirements
- Difficulty in recruiting and training skilled annotators with domain expertise exacerbates delays and variability in data quality across projects
- Annotation inconsistencies and quality control issues necessitate rework and layered review processes that add to time and expense. Growing dataset sizes driven by advances in AI model complexity intensify the annotation demand, further stretching human resources and budgets
- The industry is actively exploring semi-automated and AI-assisted annotation tools to reduce costs and turnaround time, but wide adoption is still challenged by model reliability and integration complexities
AI Training Dataset Market Scope
The market is segmented on the basis of software, type, and vertical.
- By Software
On the basis of software, the AI training dataset market is segmented into Data Collection Tools, Data Annotation Software, and Off-the-Shelf Datasets. The Data Annotation Software segment dominated the market in 2024, owing to its critical role in generating high-quality labeled data, essential for training supervised learning models in sectors such as automotive, healthcare, and retail. These platforms support a range of data types, including image, text, audio, and video, and often come equipped with AI-assisted annotation features that speed up the labeling process. Enterprises prefer these tools for their ability to handle large datasets, enable real-time collaboration among distributed teams, and ensure consistency in labeling tasks. Their widespread integration with machine learning pipelines and compatibility with multiple model training frameworks further reinforce their dominance.
The Off-the-Shelf Datasets segment is anticipated to experience the fastest CAGR from 2025 to 2032, driven by growing demand from companies aiming to reduce time-to-market for their AI solutions. These pre-labeled datasets come curated for specific domains such as facial recognition, fraud detection, or medical imaging, allowing AI teams to skip the time-consuming data collection phase. Startups and small enterprises, in particular, benefit from their affordability, speed, and quality assurance. In addition, as model generalization becomes a key focus, off-the-shelf datasets are increasingly sought for benchmarking and pretraining purposes, especially in transfer learning and foundation model development.
- By Type
On the basis of type, the AI training dataset market is segmented into Image/Video, Audio, and Text. The Image/Video segment accounted for the largest share of 41.5% in 2024, owing to the explosion in computer vision applications such as facial authentication, autonomous driving, medical diagnostics, and retail surveillance. These models require vast volumes of annotated images and video frames to identify, classify, and track objects with high precision. The rapid growth of edge devices and embedded vision in drones, robotics, and smart infrastructure further fuels demand for visual datasets. Organizations are also increasingly leveraging synthetic image and video datasets to supplement real-world data, improving model robustness under varied environmental conditions.
The Audio segment is expected to record the highest growth rate from 2025 to 2032, supported by the widespread use of AI in voice-driven applications including virtual assistants, call center automation, and multilingual transcription services. Annotated audio datasets with speech, acoustic events, and background noise contexts are critical for improving accuracy in speech recognition and sound classification tasks. Growth is further accelerated by increasing R&D in emotionally aware voice AI and accessibility technologies for the visually impaired. With rising demand for voice data in regional languages and dialects, dataset providers are expanding offerings to support diversified linguistic and acoustic profiles.
- By Vertical
On the basis of vertical, the AI training dataset market is segmented into IT, Automotive, Government, Healthcare, BFSI, and Retail & E-commerce. The IT segment led the market in 2024, as tech firms and cloud service providers invest heavily in training AI for cybersecurity, automation, and customer experience enhancement. These organizations often develop in-house datasets or procure massive volumes of structured and unstructured data to support model development, testing, and continuous learning. The rapid pace of software innovation and AI integration across platforms and services fuels ongoing demand for diverse, task-specific datasets. Moreover, the IT sector's access to advanced tools for data labeling and processing allows it to maintain leadership in dataset utilization.
The Healthcare segment is projected to witness the fastest growth from 2025 to 2032, driven by the increasing adoption of AI in disease diagnosis, imaging analysis, robotic surgery, and patient management systems. Training AI models in this sector requires large, well-curated datasets such as MRI scans, pathology slides, genomics data, and clinical notes, which must adhere to strict regulatory and ethical standards. The rise in public-private collaborations, such as hospitals partnering with AI firms for data-driven innovations, is boosting dataset accessibility. In addition, the push for personalized and predictive healthcare is accelerating demand for longitudinal and multimodal patient data, making healthcare a high-growth vertical for AI training datasets.
AI Training Dataset Market Regional Analysis
- North America dominated the AI training dataset market with the largest revenue share of 36.3% in 2024, driven by the region's strong AI ecosystem, extensive R&D investments, and the presence of major tech firms and AI startups
- Enterprises in North America are heavily investing in AI model training for applications in healthcare, finance, autonomous driving, and cybersecurity, thereby increasing the demand for diverse and high-quality training datasets
- The region benefits from advanced cloud infrastructure, high digital literacy, and favorable regulatory support for AI innovation, contributing to large-scale dataset procurement and usage across industries
U.S. AI Training Dataset Market Insight
The U.S. AI training dataset market captured the largest revenue share in 2024 within North America, propelled by robust AI adoption across industries such as healthcare, automotive, and IT. The rapid development of machine learning and natural language processing applications continues to generate demand for labeled data, particularly in image, speech, and text formats. Tech giants and startups alike are leveraging massive volumes of training data to develop proprietary AI models. Public-private partnerships, government-backed research, and an innovation-focused academic sector further accelerate the dataset ecosystem in the U.S.
Europe AI Training Dataset Market Insight
The Europe AI training dataset market is projected to grow at a substantial CAGR during the forecast period, supported by stringent data privacy regulations and an increasing focus on ethical AI development. The rise in automation, AI-driven public services, and smart manufacturing are driving the demand for high-quality datasets across the continent. European enterprises are emphasizing the use of explainable and unbiased datasets, aligning with GDPR compliance and ethical standards. Adoption is notably strong in sectors such as automotive, healthcare, and government where precision-trained AI models are critical.
U.K. AI Training Dataset Market Insight
The U.K. AI training dataset market is expected to grow at a significant CAGR during the forecast period, fueled by national initiatives promoting AI leadership and digital transformation. With investments in AI research hubs and growing demand for intelligent automation in sectors such as BFSI and e-commerce, the need for reliable, pre-labeled datasets is rising. The U.K.'s vibrant startup ecosystem and strong presence of AI-as-a-service providers further enhance the market. Emphasis on responsible AI and fair data usage is encouraging the development of high-quality, bias-free datasets.
Germany AI Training Dataset Market Insight
The Germany AI training dataset market is anticipated to expand steadily, driven by the country’s leadership in industrial automation, smart mobility, and healthcare digitization. German organizations are increasingly adopting AI in areas such as predictive maintenance, autonomous vehicles, and medical diagnostics, all of which require precise and domain-specific datasets. The market benefits from collaboration between research institutions, corporates, and government-backed AI initiatives. Germany’s focus on quality, data protection, and innovation supports the demand for secure, scalable training data solutions.
Asia-Pacific AI Training Dataset Market Insight
The Asia-Pacific AI training dataset market is expected to grow at the fastest CAGR during the forecast period of 2025 to 2032, driven by rapid digital transformation, expanding AI use cases, and increasing government support for AI development in economies such as China, Japan, India, and South Korea. The proliferation of internet-connected devices, multilingual populations, and mobile-first markets is creating diverse data needs. In addition, APAC's role as a global hub for AI talent and cost-efficient data labeling services further accelerates dataset production and consumption across verticals.
Japan AI Training Dataset Market Insight
The Japan AI training dataset market is growing steadily, underpinned by the country's emphasis on robotics, smart cities, and intelligent transport systems. Japan’s highly advanced digital infrastructure and the widespread use of connected devices are generating large volumes of structured and unstructured data. Enterprises are actively utilizing AI to address labor shortages and aging population challenges, especially in healthcare and logistics. Demand for multimodal and language-specific datasets is rising as AI adoption expands into consumer electronics and public services.
China AI Training Dataset Market Insight
The China AI training dataset market accounted for the largest revenue share in Asia Pacific in 2024, driven by the country’s AI-first development strategy, large-scale digitization, and dominance in smart devices. The widespread deployment of facial recognition, surveillance, and e-commerce AI systems has generated massive demand for labeled datasets. Government-backed programs and the rise of domestic AI companies have created a robust ecosystem for data generation, annotation, and distribution. China’s thriving smart city and autonomous vehicle initiatives continue to create vast opportunities for dataset providers.
AI Training Dataset Market Share
The AI training dataset industry is primarily led by well-established companies, including:
- Scale AI (U.S.)
- Appen (Australia)
- Lionbridge (U.S.)
- AWS (U.S.)
- Sama (U.S.)
- Clickworker (U.K.)
- Cogito Tech (U.S.)
- CloudFactory (U.K.)
- TELUS International (Canada)
- Innodata (U.S.)
- iMerit (U.S.)
- TransPerfect (U.S.)
- Google (U.S.)
- LXT (Canada)
- IBM (U.S.)
- Microsoft (U.S.)
- NVIDIA (U.S.)
Latest Developments in Global AI Training Dataset Market
- In September 2024, Innodata launched its AI Data Marketplace, marking a significant step toward addressing data scalability and accessibility challenges in AI/ML model training. The platform offers curated, on-demand synthetic document datasets, which help data science teams overcome limitations related to data volume, diversity, and privacy. By simplifying access to ready-to-use datasets, this marketplace is expected to accelerate AI model development and support the increasing demand for synthetic and domain-specific training data across industries
- In September 2024, SCALE AI announced a $21 million investment in nine AI-driven healthcare projects across Canada, under the Pan-Canadian Artificial Intelligence Strategy. This initiative is set to significantly impact the AI training dataset market in the healthcare domain by promoting collaboration between hospitals and AI developers. It aims to improve patient care, reduce wait times, and optimize healthcare operations, thereby increasing demand for high-quality, ethically sourced datasets tailored for clinical, administrative, and diagnostic applications
- In August 2024, Lionbridge Technologies, Inc. introduced Aurora AI Studio, a dedicated platform focused on assisting enterprises in training AI models with high-quality datasets. This launch addresses the growing need for specialized and well-annotated data to support advanced AI use cases. By leveraging Lionbridge’s global expertise in data curation and annotation, the platform strengthens the commercial AI ecosystem and is poised to influence demand for tailored, multilingual, and industry-specific datasets in sectors such as finance, retail, and telecommunications
- In August 2024, Accenture in partnership with Google Cloud accelerated the deployment of generative AI solutions through their Generative AI Center of Excellence. With 45% of projects transitioning into production, this collaboration highlights the increasing operationalization of AI at scale. It underscores the urgent requirement for secure, diverse, and production-ready training datasets that support advanced AI models across enterprises. The initiative also integrates cybersecurity, reinforcing the role of responsible data handling and privacy-focused datasets in enterprise AI adoption
- In July 2024, Microsoft Research unveiled AgentInstruct, a multi-agent workflow framework designed to automate the generation of high-quality synthetic data. Demonstrated through improvements in its Orca-3 model across various benchmarks, this framework minimizes human intervention in data labeling, thereby reducing costs and accelerating dataset creation. AgentInstruct is expected to reshape the AI training dataset market by advancing the use of synthetic data for large-scale model training, particularly in generative AI and foundation models
SKU-
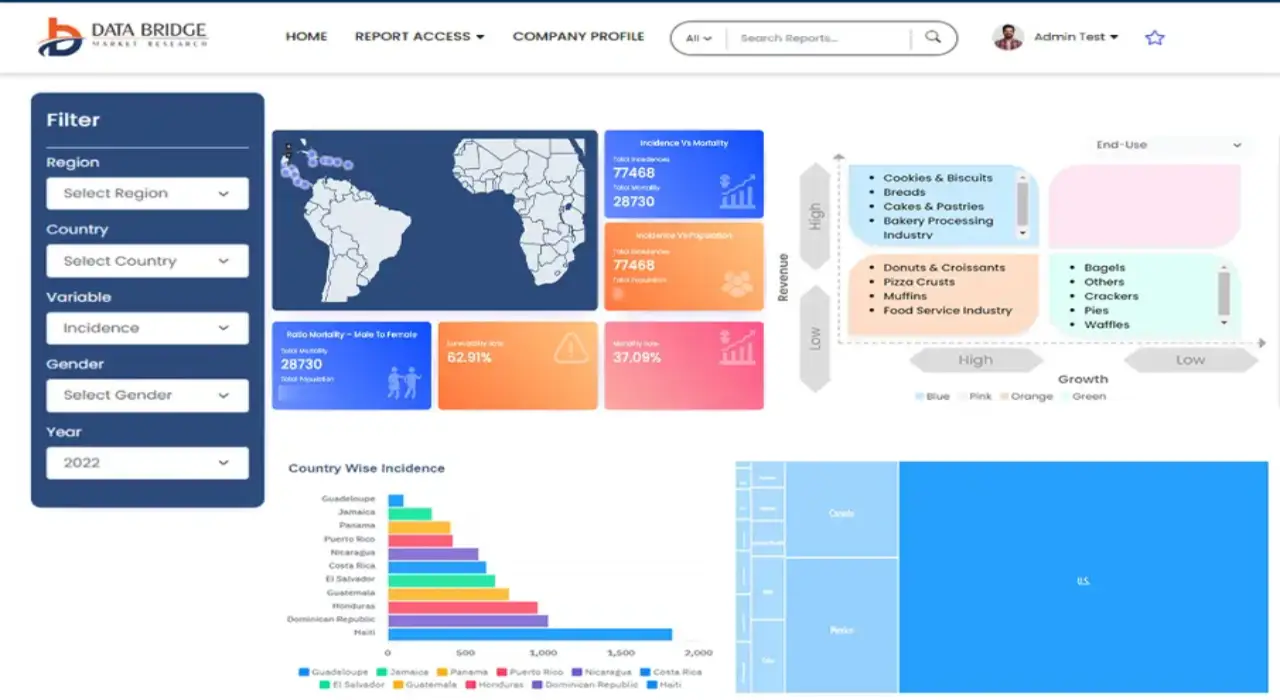
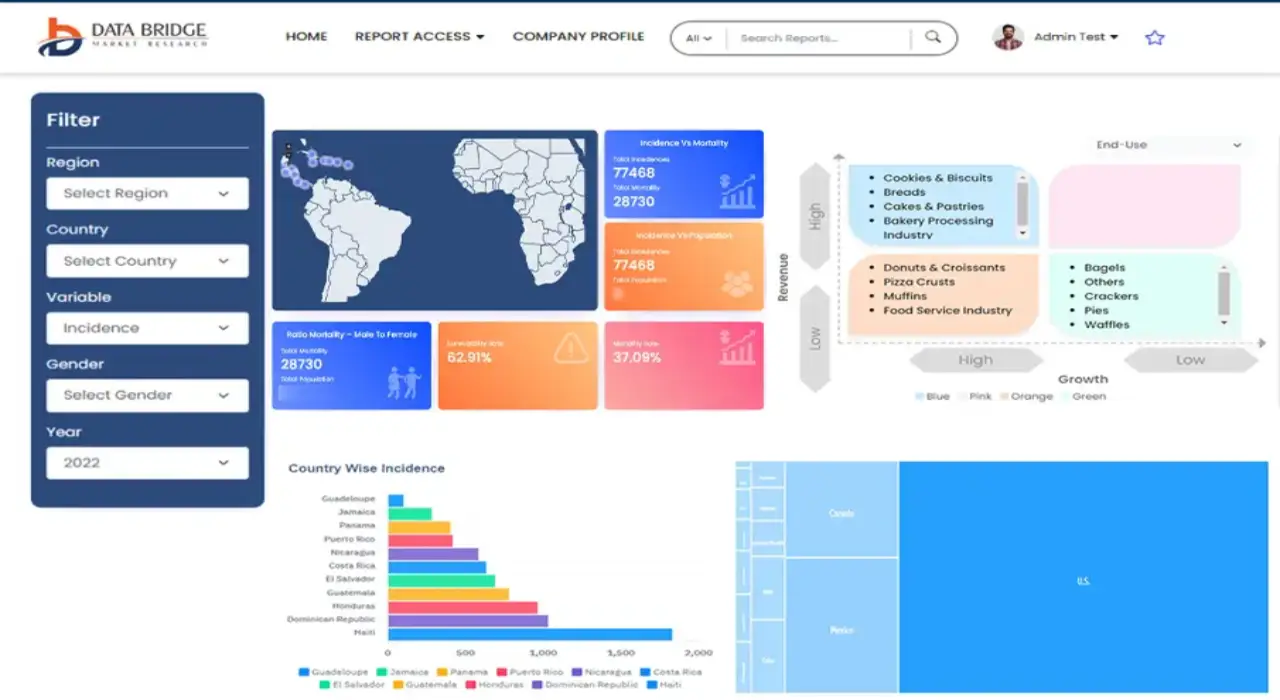
- Interactive Data Analysis Dashboard
- Company Analysis Dashboard for high growth potential opportunities
- Research Analyst Access for customization & queries
- Competitor Analysis with Interactive dashboard
- Latest News, Updates & Trend analysis
- Harness the Power of Benchmark Analysis for Comprehensive Competitor Tracking
Data collection and base year analysis are done using data collection modules with large sample sizes. The stage includes obtaining market information or related data through various sources and strategies. It includes examining and planning all the data acquired from the past in advance. It likewise envelops the examination of information inconsistencies seen across different information sources. The market data is analysed and estimated using market statistical and coherent models. Also, market share analysis and key trend analysis are the major success factors in the market report. To know more, please request an analyst call or drop down your inquiry.
The key research methodology used by DBMR research team is data triangulation which involves data mining, analysis of the impact of data variables on the market and primary (industry expert) validation. Data models include Vendor Positioning Grid, Market Time Line Analysis, Market Overview and Guide, Company Positioning Grid, Patent Analysis, Pricing Analysis, Company Market Share Analysis, Standards of Measurement, Global versus Regional and Vendor Share Analysis. To know more about the research methodology, drop in an inquiry to speak to our industry experts.
Data Bridge Market Research is a leader in advanced formative research. We take pride in servicing our existing and new customers with data and analysis that match and suits their goal. The report can be customized to include price trend analysis of target brands understanding the market for additional countries (ask for the list of countries), clinical trial results data, literature review, refurbished market and product base analysis. Market analysis of target competitors can be analyzed from technology-based analysis to market portfolio strategies. We can add as many competitors that you require data about in the format and data style you are looking for. Our team of analysts can also provide you data in crude raw excel files pivot tables (Fact book) or can assist you in creating presentations from the data sets available in the report.