Global Content Detection Market
Размер рынка в млрд долларов США
CAGR :
% 
 USD
16.92 Billion
USD
54.33 Billion
2024
2032
USD
16.92 Billion
USD
54.33 Billion
2024
2032
| 2025 –2032 | |
| USD 16.92 Billion | |
| USD 54.33 Billion | |
| % | |
|
Сегментация мирового рынка обнаружения контента по подходу к обнаружению контента (проверка контента с помощью ИИ, модерация контента и обнаружение плагиата), типу контента (текст, изображение, аудио и видео), конечному использованию (платформы социальных сетей, обработка естественного языка (NLP), розничная торговля и электронная коммерция, игровые платформы и другие) — тенденции отрасли и прогноз до 2032 года
Размер рынка обнаружения контента
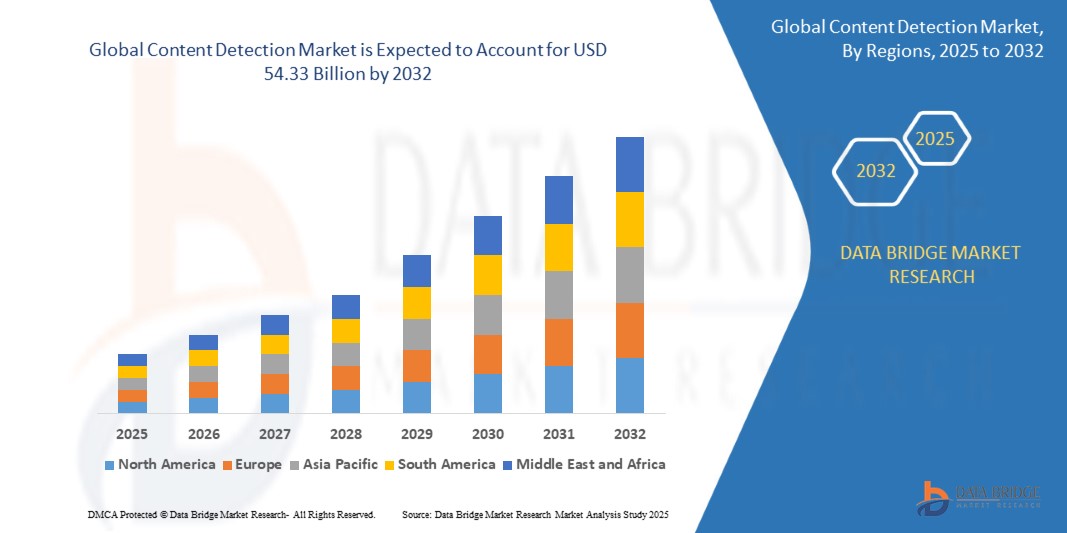
- Объем мирового рынка обнаружения контента в 2024 году оценивался в 16,92 млрд долларов США, а к 2032 году , как ожидается, он достигнет 54,33 млрд долларов США при среднегодовом темпе роста 15,70% в течение прогнозируемого периода.
- Рост рынка во многом обусловлен экспоненциальным ростом объёмов создания цифрового контента в социальных сетях, электронной коммерции, образовании и на корпоративных платформах, что обуславливает острую потребность в решениях для обеспечения подлинности, соответствия требованиям и безопасности бренда. Растущее распространение дезинформации, плагиата и дипфейков, создаваемых искусственным интеллектом, сделало передовые технологии обнаружения незаменимыми для защиты как бизнеса, так и потребителей в цифровом пространстве.
- Более того, растущее давление со стороны регулирующих органов в сочетании с растущим спросом на безопасные, надёжные и этически согласованные цифровые экосистемы ускоряют внедрение инструментов обнаружения контента на базе искусственного интеллекта. Эти факторы значительно увеличивают инвестиции в системы обнаружения, превращая их в ключевой компонент стратегий цифрового управления и кибербезопасности.
Анализ рынка обнаружения контента
- Технологии обнаружения контента включают в себя решения на базе искусственного интеллекта, предназначенные для анализа, проверки и модерации текстов, изображений, аудио- и видеоматериалов с целью обеспечения их уникальности, подлинности и соответствия требованиям. Эти инструменты широко применяются в таких отраслях, как социальные сети, издательское дело, наука, электронная коммерция и игры, для выявления плагиата, выявления сфальсифицированных медиаконтента и защиты интеллектуальной собственности.
- Растущий спрос на решения для обнаружения контента обусловлен, прежде всего, растущим проникновением генеративного ИИ, растущим риском дезинформации и необходимостью модерации контента в режиме реального времени. Поскольку предприятия, государственные учреждения и академические учреждения уделяют всё больше внимания прозрачности и цифровому доверию, рынок обнаружения контента демонстрирует уверенный рост как в развитых, так и в развивающихся странах.
- Северная Америка доминировала на рынке обнаружения контента с долей 39,2% в 2024 году благодаря растущему распространению дезинформации, росту потребления цифрового контента и сильному присутствию ведущих поставщиков технологий ИИ.
- Ожидается, что Азиатско-Тихоокеанский регион станет самым быстрорастущим регионом на рынке обнаружения контента в течение прогнозируемого периода из-за бурного развития цифровизации, растущего проникновения Интернета и быстрого развития социальных сетей и платформ электронной коммерции.
- Сегмент модерации контента доминировал на рынке с долей 54,6% в 2024 году благодаря резкому росту пользовательского контента на платформах социальных сетей, форумах и стриминговых сервисах. Компании активно инвестируют в инструменты модерации для фильтрации вредоносных, жестоких или оскорбительных материалов, обеспечивая соблюдение государственных норм и защищая репутацию бренда. Решения для модерации на базе искусственного интеллекта всё чаще интегрируются с обработкой естественного языка и компьютерным зрением, что позволяет сканировать большие объёмы текста, изображений и видео в режиме реального времени. Ожидается, что растущий потребительский спрос на более безопасную цифровую среду ускорит развитие этого сегмента в ближайшие годы.
Сегментация рынка области охвата и содержания отчета
|
Атрибуты |
Ключевые идеи рынка обнаружения контента |
|
Охваченные сегменты |
|
|
Страны действия |
Северная Америка
Европа
Азиатско-Тихоокеанский регион
Ближний Восток и Африка
Южная Америка
|
|
Ключевые игроки рынка |
|
|
Рыночные возможности |
|
|
Информационные наборы данных с добавленной стоимостью |
Помимо таких рыночных данных, как рыночная стоимость, темпы роста, сегменты рынка, географический охват, участники рынка и рыночный сценарий, отчет о рынке, подготовленный командой Data Bridge Market Research, включает в себя углубленный экспертный анализ, анализ импорта/экспорта, анализ цен, анализ потребления продукции и анализ пестицидов. |
Тенденции рынка обнаружения контента
Растущее использование ИИ и машинного обучения для обнаружения контента
- Растущая интеграция искусственного интеллекта (ИИ) и машинного обучения (МО) в системы обнаружения контента трансформирует рынок, повышая точность, масштабируемость и эффективность. Поскольку объём цифрового контента продолжает расти экспоненциально, передовые решения на базе ИИ становятся критически важными для выявления вредоносных, вводящих в заблуждение или неприемлемых материалов на различных платформах.
- Например, такие компании, как Microsoft и Google, внедряют инструменты обнаружения на основе искусственного интеллекта, которые ежедневно проверяют миллиарды единиц контента, выявляя дезинформацию, разжигание ненависти и нарушения авторских прав в режиме реального времени. Аналогичным образом, такие стартапы, как Clarifai и Hive, используют инструменты компьютерного зрения и глубокого обучения для более точного выявления манипуляций с медиаконтентом, включая дипфейки и откровенный визуальный контент.
- Модели искусственного интеллекта и машинного обучения обеспечивают значительные преимущества благодаря постоянному обучению и адаптации к новым методам манипулирования контентом. Эта адаптивность повышает эффективность обнаружения в средах, где злоумышленники часто меняют свою тактику, чтобы обойти традиционные ручные и основанные на правилах системы мониторинга.
- Растущее использование технологий обработки естественного языка (NLP) и компьютерного зрения на базе искусственного интеллекта позволяет платформам автоматизировать масштабную проверку контента, одновременно снижая нагрузку на человека. Более того, предиктивное выявление подозрительного контента до того, как он станет вирусным, укрепляет доверие к цифровым платформам и снижает репутационные риски.
- Подводя итог, можно сказать, что растущее внедрение технологий искусственного интеллекта и машинного обучения является ключевой тенденцией, определяющей развитие рынка обнаружения контента. Эти технологии позволяют быстрее обнаруживать вредоносный контент в больших масштабах, одновременно обеспечивая отрасли долгосрочный рост в условиях всё более сложной цифровой экосистемы.
Динамика рынка обнаружения контента
Водитель
Рост числа случаев дезинформации и дипфейков
- Резкий рост объёмов дезинформации, дезинформации и фейкового контента является одним из основных факторов развития рынка обнаружения контента. Социальные сети, новостные интернет-издания и цифровые платформы всё чаще подвергаются пристальному вниманию из-за распространения ложной информации, которая влияет на общественное мнение, создаёт политическую нестабильность и подрывает корпоративную репутацию.
- Например, такие платформы, как Facebook и Twitter (теперь X), внедрили фреймворки обнаружения контента на основе искусственного интеллекта для выявления и удаления дезинформации, связанной с выборами, кризисами в области здравоохранения и социальными проблемами. Аналогичным образом, медиаорганизации сотрудничают с компаниями, специализирующимися на обнаружении, такими как NewsGuard и Graphika, чтобы отфильтровывать сфабрикованные и сфальсифицированные новости до того, как они достигнут широкой аудитории.
- Дипфейки, создаваемые с использованием передовых технологий искусственного интеллекта и синтетических медиа, представляют ещё большую угрозу, создавая высокореалистичные фейковые видео и аудиозаписи. Это вызывает обеспокоенность в различных отраслях, от политики до финансов, и повышает спрос на сложные механизмы обнаружения, способные выявлять тонкие цифровые манипуляции.
- Регулятивное давление и государственные инициативы также усиливают этот фактор. Правительства Европы, Северной Америки и Азии вводят более строгие законы о регулировании контента, вынуждая платформы инвестировать в передовые инструменты обнаружения, которые обеспечивают соблюдение требований и снижают связанные с этим штрафы и юридические риски.
- В целом, растущий объем дезинформации и растущие риски, связанные с дипфейками, существенно стимулируют устойчивый спрос на передовые решения по обнаружению контента во всем мире, усиливая их роль как критически важных факторов цифрового доверия и безопасности.
Сдержанность/Вызов
Высокий уровень ложноположительных результатов в автоматизированных системах обнаружения
- Одной из серьёзных проблем, с которыми сталкивается рынок обнаружения контента, является высокий уровень ложных срабатываний, генерируемых автоматизированными системами обнаружения. Несмотря на значительный прогресс в области алгоритмов искусственного интеллекта и машинного обучения, во многих случаях по-прежнему сложно отличить вредоносный контент от легального, особенно в таких сложных контекстах, как сатира, комментарии или культурное самовыражение.
- Например, YouTube и TikTok подверглись критике за некорректную маркировку или удаление легальных видео как вредоносного контента. Такие ошибки мешают пользователям работать с платформой, подрывают доверие к ней и создают разногласия с создателями контента и рекламодателями, которые полагаются на честные и прозрачные системы модерации.
- Ложные срабатывания также имеют эксплуатационные последствия. Чрезмерная блокировка часто увеличивает административную нагрузку, поскольку помеченный контент требует проверки человеком, что сводит на нет эффективность автоматического обнаружения. Такая гибридная зависимость увеличивает расходы и одновременно раздражает пользователей, пострадавших от необоснованных ограничений.
- Более того, такие отрасли, как журналистика, наука и индустрия развлечений, требуют контекстной точности. Автоматизированные инструменты, которые не могут правильно интерпретировать контекст, рискуют подавить свободу слова и спровоцировать негативную реакцию на репутацию платформ.
- В результате высокий уровень ложноположительных результатов остаётся серьёзным сдерживающим фактором на рынке. Решение этой проблемы потребует постоянного совершенствования моделей искусственного интеллекта и машинного обучения, более широкого использования инструментов контекстного анализа и более тесной интеграции человеческого контроля с системами машинного обнаружения для достижения баланса между точностью, объективностью и масштабируемостью.
Сфера применения рынка обнаружения контента
Рынок сегментирован на основе подхода к обнаружению контента, типа контента и конечного использования.
• По подходу обнаружения контента
На основе подхода рынок обнаружения контента сегментируется на верификацию контента с помощью ИИ, модерацию контента и обнаружение плагиата. Сегмент модерации контента с помощью ИИ занял наибольшую долю рынка в 54,6% в 2024 году, что обусловлено резким ростом объёма пользовательского контента в социальных сетях, на форумах и в стриминговых сервисах. Компании активно инвестируют в инструменты модерации для фильтрации вредоносных, жестоких или оскорбительных материалов, обеспечивая соблюдение государственных норм и защищая репутацию бренда. Решения для модерации на базе ИИ всё чаще интегрируются с обработкой естественного языка и компьютерным зрением, что позволяет сканировать в режиме реального времени объёмные текстовые, графические и видеофайлы. Ожидается, что растущий потребительский спрос на более безопасную цифровую среду ускорит развитие этого сегмента в ближайшие годы.
Ожидается, что сегмент верификации контента будет демонстрировать самые высокие темпы роста в период с 2025 по 2032 год, что обусловлено растущим потоком текстов, изображений и видео, генерируемых ИИ, на цифровых платформах. Необходимость подтверждения подлинности и предотвращения дезинформации сделала инструменты верификации на основе ИИ незаменимыми в издательском деле, рекламе и академической сфере. Их передовые возможности анализа контекста, обнаружения манипуляций и подтверждения авторства делают их высокоэффективными в борьбе с дипфейками и распространением синтетических медиа. Растущее внимание со стороны регулирующих органов к поддержанию подлинности контента ещё больше усиливает внедрение решений верификации на основе ИИ.
• По типу контента
По типу контента рынок обнаружения контента сегментируется на текст, изображения, аудио и видео. Текстовый сегмент занимал наибольшую долю рынка в 2024 году, чему способствовал большой объём цифровых письменных материалов в академической среде, журналистике, блогах и корпоративных коммуникациях. Инструменты для обнаружения плагиата, проверки грамматической целостности и контекстной аутентичности получили широкое распространение для обеспечения уникальности и достоверности текстового контента. Образовательные учреждения, издательства научных исследований и компании постоянно внедряют передовые платформы обнаружения текста для минимизации рисков, связанных с интеллектуальной собственностью, и сохранения репутационной ценности. Этот сегмент также выигрывает от растущей интеграции с лингвистическими моделями на основе искусственного интеллекта, которые повышают точность выявления перефразированных или сфальсифицированных текстов.
Ожидается, что сегмент видео будет демонстрировать самые высокие среднегодовые темпы роста в период с 2025 по 2032 год, чему будет способствовать экспоненциальный рост популярности коротких видеороликов, прямых трансляций и цифровой рекламы. Обнаружение ненадлежащего, вводящего в заблуждение или созданного искусственным интеллектом видеоконтента стало критически важным приоритетом для социальных сетей, электронной коммерции и новостных вещателей. Технологии обнаружения видео используют машинное обучение и модели идентификации дипфейков для выявления сфальсифицированных визуальных материалов и предотвращения распространения вредоносных или вводящих в заблуждение сюжетов. В связи с тем, что потребление видеоконтента во всем мире опережает другие форматы, платформы активно инвестируют в масштабируемые системы обнаружения, способные анализировать загруженные видео высокой четкости в режиме реального времени.
• По конечному использованию
По принципу конечного использования рынок обнаружения контента сегментируется на платформы социальных сетей, платформы обработки естественного языка (NLP), розничную торговлю и электронную коммерцию, игровые платформы и другие. В 2024 году наибольшую долю рынка составили платформы социальных сетей, поскольку огромный поток пользовательских публикаций, изображений и видео требует постоянного мониторинга на предмет дезинформации, вредоносного контента и нарушений авторских прав. Такие платформы, как Facebook, Instagram и TikTok, внедрили сложные системы обнаружения на основе искусственного интеллекта для соблюдения нормативных требований и поддержания доверия пользователей и рекламодателей. Доминирование этого сегмента также усиливается растущим глобальным давлением, направленным на обеспечение безопасности онлайн-пространств и предотвращение вирусного распространения сфабрикованного контента.
Прогнозируется, что сегмент обработки естественного языка (NLP) будет расти самыми быстрыми темпами в период с 2025 по 2032 год благодаря его растущей роли в сфере разговорного искусственного интеллекта, поддержки клиентов и корпоративных коммуникаций. Инструменты обнаружения на основе NLP широко применяются для анализа текстовых взаимодействий в режиме реального времени, позволяя компаниям мгновенно выявлять вредоносную речь, попытки фишинга или мошеннические сообщения. Их применение быстро распространяется на сферы финансовых услуг, здравоохранения и корпоративной безопасности, где точность понимания контекста имеет решающее значение. Этот сегмент также поддерживается достижениями в области лингвистического анализа на основе искусственного интеллекта, которые улучшают обнаружение тонких языковых моделей, сленга и многоязыковых вариаций на глобальных коммуникационных платформах.
Региональный анализ рынка обнаружения контента
- Северная Америка доминировала на рынке обнаружения контента с наибольшей долей выручки в 39,2% в 2024 году, что было обусловлено растущим распространением дезинформации, ростом потребления цифрового контента и сильным присутствием ведущих поставщиков технологий ИИ.
- Организации в сфере СМИ, образования и предпринимательства активно инвестируют в современные инструменты обнаружения, чтобы гарантировать подлинность, соответствие требованиям и безопасность бренда.
- Высокие располагаемые доходы, широкое проникновение Интернета и развитая цифровая экосистема еще больше ускоряют внедрение систем обнаружения на базе искусственного интеллекта, делая Северную Америку ведущим центром инноваций в этой области.
Обзор рынка обнаружения контента в США
Рынок обнаружения контента в США в 2024 году занял наибольшую долю выручки в Северной Америке благодаря быстрому росту социальных сетей, онлайн-публикаций и электронной коммерции. Спрос на верификацию, обнаружение плагиата и модерацию в режиме реального времени с помощью ИИ растёт, поскольку потребители, компании и регулирующие органы стремятся к большей прозрачности и целостности контента. Активное внедрение облачных сервисов в сочетании с интеграцией обработки естественного языка и компьютерного зрения в корпоративные рабочие процессы дополнительно стимулирует рост рынка. Более того, растущая проблема дипфейков и дезинформации, создаваемых ИИ, значительно увеличивает инвестиции в платформы обнаружения в государственном секторе, оборонном секторе и СМИ.
Обзор европейского рынка обнаружения контента
Ожидается, что европейский рынок обнаружения контента будет расти значительными среднегодовыми темпами в течение всего прогнозируемого периода, в первую очередь благодаря строгим нормам ЕС в отношении подлинности цифрового контента и соблюдения авторских прав. Рост случаев онлайн-мошенничества, академического плагиата и манипулирования медиаконтентом побуждает предприятия и образовательные учреждения внедрять передовые системы обнаружения. Европейские потребители также всё больше обеспокоены целостностью данных и дезинформацией, что создаёт высокий спрос на инструменты на основе ИИ. В регионе наблюдается быстрая интеграция технологий обнаружения в корпоративные, академические и государственные рабочие процессы, что укрепляет перспективы рынка.
Обзор рынка обнаружения контента в Великобритании
Ожидается, что рынок обнаружения контента в Великобритании будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, что обусловлено растущей популярностью цифровых медиа и опасениями по поводу дезинформации как в политическом, так и в коммерческом контексте. Внимание страны к академической добросовестности и нормативно-правовой базе для борьбы с онлайн-вредом стимулируют внедрение этих технологий в университетах, издательствах и на технологических платформах. Процветающая цифровая экономика Великобритании и мощный сектор создания контента дополнительно способствуют расширению спектра решений для обнаружения.
Обзор рынка обнаружения контента в Германии
Ожидается, что рынок обнаружения плагиата в Германии будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, чему будет способствовать пристальное внимание страны к безопасности данных, соблюдению нормативных требований и конфиденциальности. Спрос на услуги по обнаружению плагиата в академических учреждениях и проверке контента в издательском деле неуклонно растёт. Инновационная экосистема Германии в сочетании с растущими инвестициями в ИИ и автоматизацию способствует широкому внедрению инструментов обнаружения плагиата. Растущее внимание к этичному ИИ и защите прав потребителей дополнительно согласуется со спросом на безопасные и точные системы обнаружения плагиата.
Обзор рынка обнаружения контента в Азиатско-Тихоокеанском регионе
Рынок обнаружения контента в Азиатско-Тихоокеанском регионе, как ожидается, будет расти самыми быстрыми среднегодовыми темпами в прогнозируемый период с 2025 по 2032 год благодаря бурному развитию цифровизации, повышению уровня проникновения интернета и стремительному развитию социальных сетей и платформ электронной коммерции. Такие страны, как Китай, Япония и Индия, лидируют в развертывании инструментов обнаружения на основе искусственного интеллекта для борьбы с дезинформацией, защиты интеллектуальной собственности и обеспечения соблюдения нормативных требований. Государственные инициативы по цифровой трансформации и наличие большого количества пользователей, генерирующих контент, являются ключевыми факторами роста. Регион также становится экономически эффективным центром разработки и масштабирования передовых решений для обнаружения.
Обзор рынка обнаружения контента в Японии
Рынок обнаружения контента в Японии набирает обороты благодаря технологически подкованному населению, развитой интернет-инфраструктуре и высокому спросу на надёжный цифровой контент. Растущее внедрение ИИ в академическом, корпоративном и медийном секторах стимулирует инвестиции в инструменты обнаружения плагиата, проверки и модерации контента. Стремление Японии поддерживать достоверность информации в сочетании с интеграцией обнаружения контента в более широкие экосистемы Интернета вещей и ИИ ускоряет рост. Более того, зависимость стареющего населения от безопасных цифровых решений ещё больше стимулирует их внедрение.
Обзор рынка обнаружения контента в Китае
В 2024 году китайский рынок обнаружения контента обеспечил наибольшую долю выручки в Азиатско-Тихоокеанском регионе, чему способствовала огромная база интернет-пользователей, быстрая урбанизация и пристальное внимание правительства к регулированию онлайн-контента. В Китае наблюдается стремительный рост социальных сетей, игр и электронной коммерции, что требует надежных инструментов модерации и проверки контента. Китайские компании, работающие в сфере искусственного интеллекта, лидируют в разработке масштабируемых технологий обнаружения, делая решения более доступными и недорогими. Национальное стремление к цифровому управлению и инициативам «умных городов» также стимулирует широкую интеграцию систем обнаружения в различных отраслях.
Доля рынка обнаружения контента
Лидерами отрасли обнаружения контента являются в основном хорошо зарекомендовавшие себя компании, в том числе:
- Microsoft (США)
- Google (США)
- Amazon (США)
- Alibaba Cloud (Китай)
- IBM (США)
- HCL Technologies (Индия)
- Huawei Cloud (Китай)
- Wipro (Индия)
- Accenture (Ирландия)
- Кларифай (США)
- Cogito Tech (США)
- TaskUS (США)
- Cognizant (США)
- Proofpoint (США)
- Concentrix (США)
- SunTec.ai (США)
- Беседо (Швеция)
- ActiveFence (США)
- Sensity (Нидерланды)
- Улей (США)
- QuillBot (США)
- Оригинальность ИИ (Канада)
- iMerit Technology (США)
- Dataloop (Израиль)
- WebPurify (США)
Последние разработки на мировом рынке обнаружения контента
- В ноябре 2024 года компания Clarifai присоединилась к проекту Berkeley AI Research (BAIR) Open Research Commons, чтобы ускорить развитие крупномасштабных моделей ИИ и мультимодального обучения. Это сотрудничество укрепляет позиции Clarifai в области прикладного ИИ, оказывая непосредственное влияние на обнаружение контента за счет улучшения компьютерного зрения, модерации контента и разработки этичного ИИ. Сочетая научные инновации с коммерческими приложениями, эта инициатива, как ожидается, будет способствовать развитию возможностей обнаружения нового поколения, которые повысят точность выявления сфальсифицированного или ненадлежащего контента.
- В сентябре 2024 года Microsoft представила новую функцию под названием «Исправление» в рамках своего API Azure AI Content Safety, предназначенную для борьбы с галлюцинациями ИИ путем автоматического выявления и исправления вводящего в заблуждение или ложного текста, генерируемого крупными языковыми моделями. Это достижение напрямую способствует развитию рынка обнаружения контента, повышая надежность и фактологическую обоснованность результатов генеративного ИИ, особенно в таких чувствительных секторах, как здравоохранение, финансы и юридические услуги. Интеграция многомасштабных языковых моделей значительно повышает доверие к платформам на базе ИИ, усиливая роль Microsoft в формировании безопасных и надежных экосистем ИИ.
- В сентябре 2024 года компания Tata Consultancy Services (TCS) расширила партнерство с Google Cloud, выпустив два решения для кибербезопасности на базе искусственного интеллекта: TCS Managed Detection and Response (MDR) и TCS Secure Cloud Foundation. Эти решения вносят свой вклад в развитие рынка обнаружения контента, интегрируя технологии обнаружения в корпоративные системы кибербезопасности, тем самым повышая устойчивость к меняющимся киберугрозам. Это сотрудничество расширяет портфель решений TCS на базе искусственного интеллекта и способствует их внедрению среди предприятий, которым требуются комплексные решения для обеспечения цифрового доверия.
- В августе 2024 года компания Meta расширила свое лицензионное соглашение с Universal Music Group, включив в него WhatsApp, распространив меры защиты контента на все свои основные коммуникационные платформы. В рамках партнерства особое внимание уделяется борьбе с несанкционированным контентом, создаваемым ИИ, обеспечению справедливой компенсации создателям и защите человеческого творчества. Этот шаг напрямую влияет на рынок обнаружения контента, стимулируя потребность в надежных системах обнаружения и модерации, способных различать медиаконтент, созданный человеком, и медиаконтент, созданный ИИ, в экосистемах социальных сетей и развлечений.
- В марте 2024 года Huawei Cloud заключила стратегическое партнерство с YASH Technologies для предоставления решений в области облачных вычислений и искусственного интеллекта (ИИ) в регионе Ближнего Востока и Северной Африки. Целью партнерства является использование возможностей Huawei в области искусственного интеллекта (ИИ) в области машинного обучения и анализа данных, что потенциально способствует совершенствованию технологий обнаружения контента в корпоративных рабочих процессах. Ожидается, что благодаря интеграции передовых технологий ИИ в региональные бизнес-экосистемы это сотрудничество расширит внедрение инструментов обнаружения контента на рынке, особенно в развивающихся странах с растущим цифровым следом.
SKU-
Получите онлайн-доступ к отчету на первой в мире облачной платформе рыночной аналитики
- Интерактивная панель анализа данных
- Панель анализа компании для возможностей с высоким потенциалом роста
- Доступ аналитика-исследователя для настройки и запросов
- Анализ конкурентов с помощью интерактивной панели
- Последние новости, обновления и анализ тенденций
- Используйте возможности сравнительного анализа для комплексного отслеживания конкурентов
Методология исследования
Сбор данных и анализ базового года выполняются с использованием модулей сбора данных с большими размерами выборки. Этап включает получение рыночной информации или связанных данных из различных источников и стратегий. Он включает изучение и планирование всех данных, полученных из прошлого заранее. Он также охватывает изучение несоответствий информации, наблюдаемых в различных источниках информации. Рыночные данные анализируются и оцениваются с использованием статистических и последовательных моделей рынка. Кроме того, анализ доли рынка и анализ ключевых тенденций являются основными факторами успеха в отчете о рынке. Чтобы узнать больше, пожалуйста, запросите звонок аналитика или оставьте свой запрос.
Ключевой методологией исследования, используемой исследовательской группой DBMR, является триангуляция данных, которая включает в себя интеллектуальный анализ данных, анализ влияния переменных данных на рынок и первичную (отраслевую экспертную) проверку. Модели данных включают сетку позиционирования поставщиков, анализ временной линии рынка, обзор рынка и руководство, сетку позиционирования компании, патентный анализ, анализ цен, анализ доли рынка компании, стандарты измерения, глобальный и региональный анализ и анализ доли поставщика. Чтобы узнать больше о методологии исследования, отправьте запрос, чтобы поговорить с нашими отраслевыми экспертами.
Доступна настройка
Data Bridge Market Research является лидером в области передовых формативных исследований. Мы гордимся тем, что предоставляем нашим существующим и новым клиентам данные и анализ, которые соответствуют и подходят их целям. Отчет можно настроить, включив в него анализ ценовых тенденций целевых брендов, понимание рынка для дополнительных стран (запросите список стран), данные о результатах клинических испытаний, обзор литературы, обновленный анализ рынка и продуктовой базы. Анализ рынка целевых конкурентов можно проанализировать от анализа на основе технологий до стратегий портфеля рынка. Мы можем добавить столько конкурентов, о которых вам нужны данные в нужном вам формате и стиле данных. Наша команда аналитиков также может предоставить вам данные в сырых файлах Excel, сводных таблицах (книга фактов) или помочь вам в создании презентаций из наборов данных, доступных в отчете.