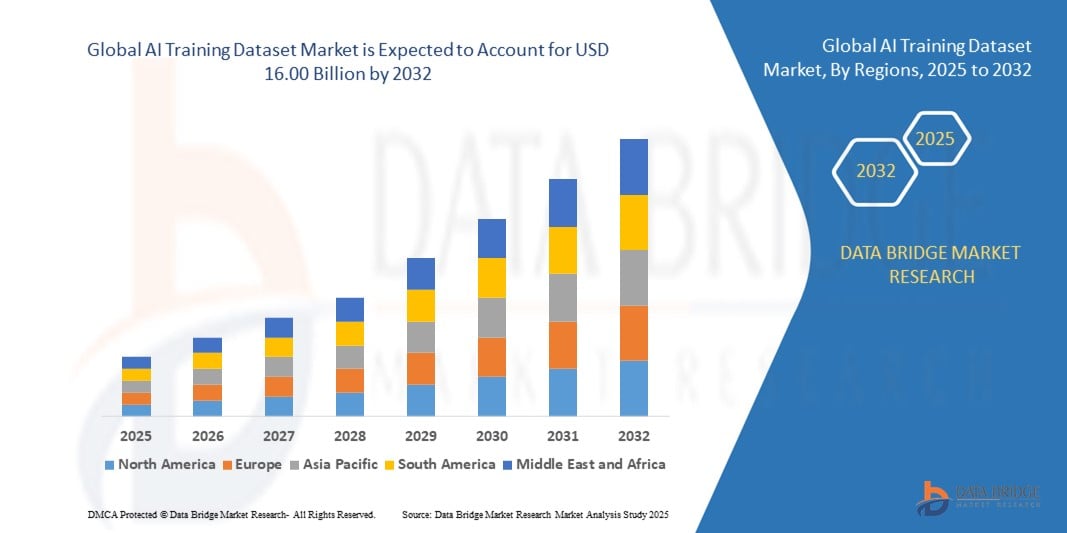
Global Ai Training Dataset Market
Marktgröße in Milliarden USD
CAGR :
% 
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 –2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
Globale Marktsegmentierung für KI-Trainingsdatensätze nach Softwaretyp (Datenerfassungstools, Datenannotationssoftware und Standarddatensätze) (Bild/Video, Audio und Text), vertikal (IT, Automobilindustrie, Behörden, Gesundheitswesen, BFSI sowie Einzelhandel und E-Commerce) – Branchentrends und Prognose bis 2032
Marktgröße für KI-Trainingsdatensätze
- Der globale Markt für KI-Trainingsdatensätze hatte im Jahr 2024 einen Wert von 2,72 Milliarden US-Dollar und wird bis 2032 voraussichtlich 16,00 Milliarden US-Dollar erreichen , bei einer CAGR von 24,80 % im Prognosezeitraum.
- Das Marktwachstum wird maßgeblich durch die zunehmende Nutzung von Technologien der künstlichen Intelligenz und des maschinellen Lernens in Sektoren wie dem Gesundheitswesen, der Automobilindustrie, dem Einzelhandel und dem Finanz- und Sicherheitssektor vorangetrieben. Dies hat zu einem starken Anstieg der Nachfrage nach hochwertigen, annotierten Trainingsdatensätzen zur Verbesserung der Modellgenauigkeit und -leistung geführt.
- Darüber hinaus veranlasst die Verbreitung datenintensiver Anwendungen – von Computer Vision und Spracherkennung bis hin zu NLP und Predictive Analytics – Unternehmen dazu, in skalierbare, domänenspezifische Datensätze zu investieren, was die Expansion der KI-Trainingsdatensatzbranche erheblich vorantreibt.
Marktanalyse für KI-Trainingsdatensätze
- KI-Trainingsdatensätze bestehen aus strukturierten oder annotierten Daten, die zum Trainieren von Machine-Learning-Modellen in überwachten und halbüberwachten Lernumgebungen verwendet werden. Diese Datensätze können Bilder, Audio, Video, Text oder multimodale Eingaben enthalten und sind unerlässlich, um KI-Systemen beizubringen, Muster zu erkennen, Vorhersagen zu treffen und Entscheidungen mit minimalem menschlichen Eingriff zu automatisieren.
- Der rasante Anstieg der KI-Entwicklung führt zu einer enormen Nachfrage nach Trainingsdaten, insbesondere in Branchen, die intelligente Systeme für Diagnose, Betrugserkennung, autonome Navigation und Empfehlungsmaschinen entwickeln. Infolgedessen verzeichnet der Markt ein robustes Wachstum, unterstützt durch steigende Investitionen in Datenannotationsdienste, synthetische Datenplattformen und KI-Marktplatz-Ökosysteme.
- Nordamerika dominierte den Markt für KI-Trainingsdatensätze mit einem Anteil von 36,3 % im Jahr 2024, was auf das starke KI-Ökosystem der Region, umfangreiche F&E-Investitionen und die Präsenz großer Technologieunternehmen und KI-Startups zurückzuführen ist.
- Der asiatisch-pazifische Raum dürfte im Prognosezeitraum aufgrund der schnellen digitalen Transformation, der zunehmenden KI-Anwendungsfälle und der zunehmenden staatlichen Unterstützung für die KI-Entwicklung in Volkswirtschaften wie China, Japan, Indien und Südkorea die am schnellsten wachsende Region im Markt für KI-Trainingsdatensätze sein.
- Das Bild-/Videosegment dominierte den Markt mit einem Marktanteil von 41,5 % im Jahr 2024, was auf die explosionsartige Zunahme von Computer-Vision-Anwendungen wie Gesichtsauthentifizierung, autonomes Fahren, medizinische Diagnostik und Einzelhandelsüberwachung zurückzuführen ist. Diese Modelle benötigen große Mengen an annotierten Bildern und Videobildern, um Objekte mit hoher Präzision zu identifizieren, zu klassifizieren und zu verfolgen. Das rasante Wachstum von Edge-Geräten und Embedded Vision in Drohnen, Robotik und intelligenter Infrastruktur treibt die Nachfrage nach visuellen Datensätzen weiter an. Unternehmen nutzen zudem zunehmend synthetische Bild- und Videodatensätze, um reale Daten zu ergänzen und so die Modellrobustheit unter unterschiedlichen Umgebungsbedingungen zu verbessern.
Berichtsumfang und Marktsegmentierung für KI-Trainingsdatensätze
|
Eigenschaften |
Wichtige Markteinblicke zum KI-Trainingsdatensatz |
|
Abgedeckte Segmente |
|
|
Abgedeckte Länder |
Nordamerika
Europa
Asien-Pazifik
Naher Osten und Afrika
Südamerika
|
|
Wichtige Marktteilnehmer |
|
|
Marktchancen |
|
|
Wertschöpfungsdaten-Infosets |
Zusätzlich zu den Markteinblicken wie Marktwert, Wachstumsrate, Marktsegmenten, geografischer Abdeckung, Marktteilnehmern und Marktszenario enthält der vom Data Bridge Market Research-Team kuratierte Marktbericht eine eingehende Expertenanalyse, Import-/Exportanalyse, Preisanalyse, Produktionsverbrauchsanalyse und PESTLE-Analyse. |
Markttrends für KI-Trainingsdatensätze
Zunehmende Nutzung synthetischer Trainingsdaten
- Der Markt für KI-Trainingsdatensätze entwickelt sich rasant, da synthetische Daten als skalierbare, datenschutzkonforme Alternative zur herkömmlichen Datenannotation an Bedeutung gewinnen und Einschränkungen im Zusammenhang mit Datenknappheit, Verzerrung und Offenlegung sensibler Informationen überwinden.
- Beispielsweise sind Unternehmen wie NVIDIA und Mostly AI auf Plattformen zur Generierung synthetischer Daten spezialisiert, die die Erstellung hochwertiger, gekennzeichneter Datensätze für das Training von Computer Vision, natürlicher Sprachverarbeitung und autonomen Systemen in Branchen wie dem Gesundheitswesen, der Automobilindustrie und dem Finanzwesen ermöglichen.
- Die Flexibilität synthetischer Daten ermöglicht die Erstellung seltener Ereignisszenarien oder ausgewogener Datensätze, wodurch Verzerrungen gemildert und die Modellgeneralisierung verbessert werden
- Die zunehmende behördliche Kontrolle der Nutzung personenbezogener Daten fördert die Einführung synthetischer Datensätze, die die Privatsphäre schützen und gleichzeitig den analytischen Nutzen aufrechterhalten.
- Fortschritte bei Generative Adversarial Networks (GANs) und Simulationstechnologien ermöglichen realistische und vielfältige synthetische Datenproben und beschleunigen so die KI-Entwicklungszyklen.
- Synthetische Datensätze werden zunehmend mit realen Datensätzen integriert, um die Trainingseffektivität zu optimieren und das Risiko einer Überanpassung in Modellen des maschinellen Lernens zu verringern.
Marktdynamik für KI-Trainingsdatensätze
Treiber
Steigende Nachfrage nach domänenspezifischen und mehrsprachigen Datensätzen in allen Branchen
- Mit der zunehmenden Verbreitung von KI in Branchen wie dem Gesundheitswesen, der Automobilindustrie, dem Einzelhandel und der Telekommunikation wächst der Bedarf an sorgfältig kuratierten domänenspezifischen und mehrsprachigen Datensätzen, um das sprach-, kontext- und aufgabenspezifische Modelltraining zu unterstützen.
- So stellen beispielsweise Appen und Lionbridge umfangreiche annotierte Datensätze in verschiedenen Sprachen und Fachbereichen bereit und unterstützen Unternehmen bei der Entwicklung robuster KI-Anwendungen im Kundenservice, in der medizinischen Diagnostik und bei autonomen Fahrzeugen, die auf lokale Märkte und regulatorische Rahmenbedingungen zugeschnitten sind.
- Die zunehmende Lokalisierung und Personalisierung von KI-Produkten erfordert hochwertige, kontextrelevante Trainingsdaten, um die Genauigkeit und die Benutzerzufriedenheit zu verbessern. Die Einhaltung branchenspezifischer Vorschriften, insbesondere im Gesundheits- und Finanzwesen, erfordert eine domänenspezifische Datenkuratierung, um sicherzustellen, dass KI-Modelle rechtlichen und ethischen Standards entsprechen.
- Die steigende Popularität von Konversations-KI, Stimmungsanalyse und Sprachübersetzungstools treibt die Nachfrage nach diversifizierten Text-, Sprach- und Bilddatensätzen in mehreren Sprachen und Dialekten an
- Strategische Partnerschaften zwischen KI-Entwicklern und Datenannotationsunternehmen ermöglichen die bedarfsgerechte Erstellung spezialisierter Datensätze und beschleunigen so die Markteinführung von KI-Lösungen.
Einschränkung/Herausforderung
Hohe Kosten und Zeitaufwand der manuellen Datenannotation
- Die manuelle Annotation bleibt aufgrund ihres arbeitsintensiven, fehleranfälligen und teuren Charakters ein kritischer Engpass. Sie erfordert oft Fachexperten und langwierige Validierungszyklen, die das Training und die Bereitstellung von KI-Modellen verlangsamen.
- Unternehmen, die beispielsweise auf die manuelle Beschriftung komplexer Bild- oder Videodatensätze angewiesen sind, wie etwa Entwickler autonomer Fahrsysteme oder Unternehmen der medizinischen Bildgebung, stehen trotz strenger Qualitätsanforderungen vor hohen Betriebskosten und Skalierbarkeitsproblemen.
- Schwierigkeiten bei der Rekrutierung und Schulung qualifizierter Annotatoren mit Fachkenntnissen führen zu Verzögerungen und Schwankungen der Datenqualität zwischen Projekten.
- Inkonsistenzen bei Annotationen und Qualitätskontrollprobleme erfordern Nacharbeit und mehrstufige Überprüfungsprozesse, die Zeit und Kosten erhöhen. Wachsende Datensätze, die durch die zunehmende Komplexität von KI-Modellen bedingt sind, erhöhen den Bedarf an Annotationen und belasten Personalressourcen und Budgets zusätzlich.
- Die Branche erforscht aktiv halbautomatische und KI-gestützte Annotationstools, um Kosten und Bearbeitungszeiten zu reduzieren. Die breite Akzeptanz wird jedoch immer noch durch die Modellzuverlässigkeit und die Komplexität der Integration erschwert.
Marktumfang für KI-Trainingsdatensätze
Der Markt ist nach Software, Typ und Branche segmentiert.
- Nach Software
Der Markt für KI-Trainingsdatensätze ist softwareseitig in Datenerfassungstools, Datenannotationssoftware und Standarddatensätze unterteilt. Das Segment Datenannotationssoftware dominierte den Markt im Jahr 2024 aufgrund seiner entscheidenden Rolle bei der Generierung hochwertiger, gekennzeichneter Daten, die für das Training überwachter Lernmodelle in Branchen wie der Automobilindustrie, dem Gesundheitswesen und dem Einzelhandel unerlässlich sind. Diese Plattformen unterstützen eine Reihe von Datentypen, darunter Bild, Text, Audio und Video, und sind häufig mit KI-gestützten Annotationsfunktionen ausgestattet, die den Kennzeichnungsprozess beschleunigen. Unternehmen bevorzugen diese Tools, da sie große Datensätze verarbeiten, die Echtzeit-Zusammenarbeit zwischen verteilten Teams ermöglichen und die Konsistenz bei Kennzeichnungsaufgaben gewährleisten können. Ihre umfassende Integration in Machine-Learning-Pipelines und die Kompatibilität mit mehreren Modelltrainings-Frameworks untermauern ihre Dominanz weiter.
Das Segment der Standarddatensätze wird voraussichtlich zwischen 2025 und 2032 die höchste durchschnittliche jährliche Wachstumsrate verzeichnen. Dies ist auf die steigende Nachfrage von Unternehmen zurückzuführen, die die Markteinführungszeit ihrer KI-Lösungen verkürzen möchten. Diese vorkonfigurierten Datensätze sind für bestimmte Bereiche wie Gesichtserkennung, Betrugserkennung oder medizinische Bildgebung kuratiert, sodass KI-Teams die zeitaufwändige Datenerfassungsphase überspringen können. Insbesondere Start-ups und kleine Unternehmen profitieren von deren Erschwinglichkeit, Geschwindigkeit und Qualitätssicherung. Da die Generalisierung von Modellen zunehmend in den Fokus rückt, werden Standarddatensätze zunehmend für Benchmarking- und Vortrainingszwecke nachgefragt, insbesondere beim Transferlernen und der Entwicklung grundlegender Modelle.
- Nach Typ
Der Markt für KI-Trainingsdatensätze ist nach Typ in Bild/Video, Audio und Text segmentiert. Das Bild-/Videosegment hatte im Jahr 2024 mit 41,5 % den größten Anteil, was auf die explosionsartige Zunahme von Computer-Vision-Anwendungen wie Gesichtsauthentifizierung, autonomes Fahren, medizinische Diagnostik und Einzelhandelsüberwachung zurückzuführen ist. Diese Modelle benötigen große Mengen an kommentierten Bildern und Videoframes, um Objekte mit hoher Präzision zu identifizieren, zu klassifizieren und zu verfolgen. Das schnelle Wachstum von Edge-Geräten und Embedded Vision in Drohnen, Robotik und intelligenter Infrastruktur treibt die Nachfrage nach visuellen Datensätzen weiter an. Unternehmen nutzen zudem zunehmend synthetische Bild- und Videodatensätze, um reale Daten zu ergänzen und so die Robustheit der Modelle unter unterschiedlichen Umgebungsbedingungen zu verbessern.
Das Audiosegment wird voraussichtlich von 2025 bis 2032 die höchste Wachstumsrate verzeichnen, unterstützt durch den weit verbreiteten Einsatz von KI in sprachgesteuerten Anwendungen, darunter virtuelle Assistenten, Callcenter-Automatisierung und mehrsprachige Transkriptionsdienste. Annotierte Audiodatensätze mit Sprach-, Akustik- und Hintergrundgeräuschkontexten sind entscheidend für die Verbesserung der Genauigkeit bei Spracherkennungs- und Klangklassifizierungsaufgaben. Das Wachstum wird durch verstärkte Forschung und Entwicklung im Bereich emotionsbewusster Sprach-KI und Barrierefreiheitstechnologien für Sehbehinderte weiter beschleunigt. Mit der steigenden Nachfrage nach Sprachdaten in Regionalsprachen und Dialekten erweitern Datensatzanbieter ihr Angebot, um diversifizierte sprachliche und akustische Profile zu unterstützen.
- Nach Vertikal
Der Markt für KI-Trainingsdatensätze ist vertikal in die Branchen IT, Automobilindustrie, öffentliche Verwaltung, Gesundheitswesen, Finanz- und Sicherheitsdienstleistungen sowie Einzelhandel und E-Commerce unterteilt. Das IT-Segment war 2024 marktführend, da Technologieunternehmen und Cloud-Dienstleister massiv in KI-Training für Cybersicherheit, Automatisierung und die Verbesserung des Kundenerlebnisses investieren. Diese Unternehmen entwickeln häufig eigene Datensätze oder beschaffen sich riesige Mengen strukturierter und unstrukturierter Daten, um Modellentwicklung, Tests und kontinuierliches Lernen zu unterstützen. Das rasante Tempo der Softwareinnovation und der KI-Integration über Plattformen und Dienste hinweg treibt die anhaltende Nachfrage nach vielfältigen, aufgabenspezifischen Datensätzen an. Darüber hinaus ermöglicht der Zugang des IT-Sektors zu fortschrittlichen Tools für die Datenkennzeichnung und -verarbeitung ihm, seine führende Position bei der Datensatznutzung zu behaupten.
Das Segment Gesundheitswesen wird voraussichtlich zwischen 2025 und 2032 das schnellste Wachstum verzeichnen, angetrieben durch den zunehmenden Einsatz von KI in der Krankheitsdiagnose, der Bildanalyse, der robotergestützten Chirurgie und Patientenmanagementsystemen. Das Training von KI-Modellen in diesem Sektor erfordert große, sorgfältig kuratierte Datensätze wie MRT-Scans, Pathologie-Objektträger, Genomdaten und klinische Notizen, die strengen regulatorischen und ethischen Standards entsprechen müssen. Die Zunahme öffentlich-privater Kooperationen, beispielsweise zwischen Krankenhäusern und KI-Unternehmen für datenbasierte Innovationen, verbessert die Zugänglichkeit von Datensätzen. Darüber hinaus beschleunigt der Vorstoß in die personalisierte und prädiktive Gesundheitsversorgung die Nachfrage nach longitudinalen und multimodalen Patientendaten und macht das Gesundheitswesen zu einem wachstumsstarken vertikalen Bereich für KI-Trainingsdatensätze.
Regionale Analyse des Marktes für KI-Trainingsdatensätze
- Nordamerika dominierte den Markt für KI-Trainingsdatensätze mit dem größten Umsatzanteil von 36,3 % im Jahr 2024, angetrieben durch das starke KI-Ökosystem der Region, umfangreiche F&E-Investitionen und die Präsenz großer Technologieunternehmen und KI-Startups.
- Unternehmen in Nordamerika investieren massiv in das Training von KI-Modellen für Anwendungen im Gesundheitswesen, im Finanzwesen, im autonomen Fahren und in der Cybersicherheit. Dadurch steigt die Nachfrage nach vielfältigen und qualitativ hochwertigen Trainingsdatensätzen.
- Die Region profitiert von einer fortschrittlichen Cloud-Infrastruktur, hoher digitaler Kompetenz und günstiger regulatorischer Unterstützung für KI-Innovationen, was zur Beschaffung und Nutzung umfangreicher Datensätze in allen Branchen beiträgt.
Markteinblick in den US-amerikanischen KI-Trainingsdatensatz
Der US-Markt für KI-Trainingsdatensätze erzielte 2024 den größten Umsatzanteil in Nordamerika, angetrieben durch die starke Verbreitung von KI in Branchen wie dem Gesundheitswesen, der Automobilindustrie und der IT. Die rasante Entwicklung von Anwendungen für maschinelles Lernen und natürliche Sprachverarbeitung führt weiterhin zu einer Nachfrage nach gekennzeichneten Daten, insbesondere in Bild-, Sprach- und Textformaten. Sowohl Technologieriesen als auch Start-ups nutzen riesige Mengen an Trainingsdaten, um proprietäre KI-Modelle zu entwickeln. Öffentlich-private Partnerschaften, staatlich geförderte Forschung und ein innovationsorientierter akademischer Sektor beschleunigen das Datensatz-Ökosystem in den USA zusätzlich.
Markteinblick in KI-Trainingsdatensätze für Europa
Der europäische Markt für KI-Trainingsdatensätze wird im Prognosezeitraum voraussichtlich mit einer deutlichen jährlichen Wachstumsrate wachsen, unterstützt durch strenge Datenschutzbestimmungen und einen zunehmenden Fokus auf ethische KI-Entwicklung. Die zunehmende Automatisierung, KI-gestützte öffentliche Dienste und intelligente Fertigung treiben die Nachfrage nach hochwertigen Datensätzen auf dem gesamten Kontinent an. Europäische Unternehmen legen Wert auf die Verwendung erklärbarer und unvoreingenommener Datensätze, die DSGVO-konform und ethischen Standards entsprechen. Besonders stark ist die Akzeptanz in Branchen wie der Automobilindustrie, dem Gesundheitswesen und dem öffentlichen Dienst, in denen präzisionstrainierte KI-Modelle von entscheidender Bedeutung sind.
Markteinblick in den britischen KI-Trainingsdatensatz
Der britische Markt für KI-Trainingsdatensätze wird im Prognosezeitraum voraussichtlich mit einer signifikanten jährlichen Wachstumsrate wachsen, angetrieben durch nationale Initiativen zur Förderung von KI-Führungspositionen und digitaler Transformation. Mit Investitionen in KI-Forschungszentren und der wachsenden Nachfrage nach intelligenter Automatisierung in Sektoren wie BFSI und E-Commerce steigt der Bedarf an zuverlässigen, vorgelabelten Datensätzen. Das dynamische Startup-Ökosystem in Großbritannien und die starke Präsenz von KI-as-a-Service-Anbietern stärken den Markt zusätzlich. Der Schwerpunkt auf verantwortungsvoller KI und fairer Datennutzung fördert die Entwicklung hochwertiger, vorurteilsfreier Datensätze.
Markteinblick in den KI-Trainingsdatensatz in Deutschland
Der deutsche Markt für KI-Trainingsdatensätze wird voraussichtlich stetig wachsen, angetrieben durch die führende Rolle Deutschlands in den Bereichen Industrieautomatisierung, intelligente Mobilität und Digitalisierung des Gesundheitswesens. Deutsche Unternehmen setzen zunehmend KI in Bereichen wie vorausschauender Wartung, autonomen Fahrzeugen und medizinischer Diagnostik ein, die alle präzise und domänenspezifische Datensätze erfordern. Der Markt profitiert von der Zusammenarbeit zwischen Forschungseinrichtungen, Unternehmen und staatlich geförderten KI-Initiativen. Deutschlands Fokus auf Qualität, Datenschutz und Innovation unterstützt die Nachfrage nach sicheren, skalierbaren Trainingsdatenlösungen.
Markteinblick in KI-Trainingsdatensätze im asiatisch-pazifischen Raum
Der Markt für KI-Trainingsdatensätze im asiatisch-pazifischen Raum wird im Prognosezeitraum von 2025 bis 2032 voraussichtlich die höchste durchschnittliche jährliche Wachstumsrate (CAGR) aufweisen. Dies ist auf die schnelle digitale Transformation, die Ausweitung der KI-Anwendungsfälle und die zunehmende staatliche Unterstützung der KI-Entwicklung in Volkswirtschaften wie China, Japan, Indien und Südkorea zurückzuführen. Die zunehmende Verbreitung internetfähiger Geräte, mehrsprachiger Bevölkerungen und mobiler Märkte führt zu einem vielfältigen Datenbedarf. Darüber hinaus beschleunigt die Rolle des asiatisch-pazifischen Raums als globale Drehscheibe für KI-Talente und kosteneffiziente Datenkennzeichnungsdienste die Produktion und Nutzung von Datensätzen branchenübergreifend weiter.
Markteinblick in den japanischen KI-Trainingsdatensatz
Der japanische Markt für KI-Trainingsdatensätze wächst stetig, unterstützt durch den Schwerpunkt des Landes auf Robotik, Smart Cities und intelligente Transportsysteme. Japans hochentwickelte digitale Infrastruktur und die weit verbreitete Nutzung vernetzter Geräte generieren große Mengen strukturierter und unstrukturierter Daten. Unternehmen nutzen KI aktiv, um dem Arbeitskräftemangel und den Herausforderungen der alternden Bevölkerung zu begegnen, insbesondere im Gesundheitswesen und in der Logistik. Die Nachfrage nach multimodalen und sprachspezifischen Datensätzen steigt, da KI zunehmend auch in der Unterhaltungselektronik und im öffentlichen Dienst Einzug hält.
Markteinblick in den KI-Trainingsdatensatz in China
Der chinesische Markt für KI-Trainingsdatensätze erzielte 2024 den größten Umsatzanteil im asiatisch-pazifischen Raum. Dies ist auf die KI-orientierte Entwicklungsstrategie des Landes, die umfassende Digitalisierung und die Dominanz im Bereich intelligenter Geräte zurückzuführen. Der weit verbreitete Einsatz von KI-Systemen für Gesichtserkennung, Überwachung und E-Commerce hat eine enorme Nachfrage nach gekennzeichneten Datensätzen ausgelöst. Staatlich geförderte Programme und der Aufstieg inländischer KI-Unternehmen haben ein robustes Ökosystem für die Datengenerierung, -annotation und -verteilung geschaffen. Chinas florierende Smart-City- und autonome Fahrzeuginitiativen bieten weiterhin enorme Möglichkeiten für Datensatzanbieter.
Marktanteil von KI-Trainingsdatensätzen
Die Branche der KI-Trainingsdatensätze wird hauptsächlich von etablierten Unternehmen angeführt, darunter:
- Scale AI (USA)
- Appen (Australien)
- Lionbridge (USA)
- AWS (USA)
- Sama (USA)
- Clickworker (Großbritannien)
- Cogito Tech (USA)
- CloudFactory (Großbritannien)
- TELUS International (Kanada)
- Innodata (USA)
- iMerit (USA)
- TransPerfect (USA)
- Google (USA)
- LXT (Kanada)
- IBM (USA)
- Microsoft (US)
- NVIDIA (USA)
Neueste Entwicklungen auf dem globalen Markt für KI-Trainingsdatensätze
- Im September 2024 startete Innodata seinen AI Data Marketplace und markierte damit einen wichtigen Schritt zur Bewältigung der Herausforderungen hinsichtlich Datenskalierbarkeit und -zugänglichkeit beim Training von KI/ML-Modellen. Die Plattform bietet kuratierte, bedarfsgerechte synthetische Dokumentdatensätze, die Data-Science-Teams helfen, Einschränkungen in Bezug auf Datenvolumen, -vielfalt und Datenschutz zu überwinden. Durch den vereinfachten Zugriff auf einsatzbereite Datensätze soll dieser Marktplatz die Entwicklung von KI-Modellen beschleunigen und die steigende Nachfrage nach synthetischen und domänenspezifischen Trainingsdaten branchenübergreifend unterstützen.
- Im September 2024 kündigte SCALE AI im Rahmen der pankanadischen Strategie für künstliche Intelligenz eine Investition von 21 Millionen Dollar in neun KI-gestützte Gesundheitsprojekte in ganz Kanada an. Diese Initiative wird den Markt für KI-Trainingsdatensätze im Gesundheitswesen maßgeblich beeinflussen, indem sie die Zusammenarbeit zwischen Krankenhäusern und KI-Entwicklern fördert. Ziel ist es, die Patientenversorgung zu verbessern, Wartezeiten zu verkürzen und die Abläufe im Gesundheitswesen zu optimieren. Dadurch steigt die Nachfrage nach hochwertigen, ethisch einwandfreien Datensätzen für klinische, administrative und diagnostische Anwendungen.
- Im August 2024 stellte Lionbridge Technologies, Inc. Aurora AI Studio vor, eine dedizierte Plattform, die Unternehmen beim Training von KI-Modellen mit hochwertigen Datensätzen unterstützt. Diese Einführung trägt dem wachsenden Bedarf an spezialisierten und gut annotierten Daten zur Unterstützung fortgeschrittener KI-Anwendungsfälle Rechnung. Durch die Nutzung der globalen Expertise von Lionbridge in der Datenkuratierung und -annotation stärkt die Plattform das kommerzielle KI-Ökosystem und wird die Nachfrage nach maßgeschneiderten, mehrsprachigen und branchenspezifischen Datensätzen in Branchen wie Finanzen, Einzelhandel und Telekommunikation beeinflussen.
- Im August 2024 beschleunigte Accenture in Partnerschaft mit Google Cloud die Einführung generativer KI-Lösungen über sein Generative AI Center of Excellence. 45 % der Projekte gehen in die Produktion über. Diese Zusammenarbeit unterstreicht die zunehmende Operationalisierung von KI im großen Maßstab. Sie unterstreicht den dringenden Bedarf an sicheren, vielfältigen und produktionsreifen Trainingsdatensätzen, die fortschrittliche KI-Modelle in Unternehmen unterstützen. Die Initiative integriert auch Cybersicherheit und stärkt die Rolle eines verantwortungsvollen Umgangs mit Daten und datenschutzorientierter Datensätze bei der Einführung von KI in Unternehmen.
- Im Juli 2024 stellte Microsoft Research AgentInstruct vor, ein Multi-Agenten-Workflow-Framework zur automatisierten Generierung hochwertiger synthetischer Daten. Verbesserungen des Orca-3-Modells in verschiedenen Benchmarks zeigten, dass dieses Framework menschliche Eingriffe in die Datenbeschriftung minimiert, wodurch Kosten gesenkt und die Datensatzerstellung beschleunigt wird. AgentInstruct dürfte den Markt für KI-Trainingsdatensätze neu gestalten, indem es die Nutzung synthetischer Daten für das Training groß angelegter Modelle, insbesondere in generativer KI und Basismodellen, vorantreibt.
SKU-
Erhalten Sie Online-Zugriff auf den Bericht zur weltweit ersten Market Intelligence Cloud
- Interaktives Datenanalyse-Dashboard
- Unternehmensanalyse-Dashboard für Chancen mit hohem Wachstumspotenzial
- Zugriff für Research-Analysten für Anpassungen und Abfragen
- Konkurrenzanalyse mit interaktivem Dashboard
- Aktuelle Nachrichten, Updates und Trendanalyse
- Nutzen Sie die Leistungsfähigkeit der Benchmark-Analyse für eine umfassende Konkurrenzverfolgung
Forschungsmethodik
Die Datenerfassung und Basisjahresanalyse werden mithilfe von Datenerfassungsmodulen mit großen Stichprobengrößen durchgeführt. Die Phase umfasst das Erhalten von Marktinformationen oder verwandten Daten aus verschiedenen Quellen und Strategien. Sie umfasst die Prüfung und Planung aller aus der Vergangenheit im Voraus erfassten Daten. Sie umfasst auch die Prüfung von Informationsinkonsistenzen, die in verschiedenen Informationsquellen auftreten. Die Marktdaten werden mithilfe von marktstatistischen und kohärenten Modellen analysiert und geschätzt. Darüber hinaus sind Marktanteilsanalyse und Schlüsseltrendanalyse die wichtigsten Erfolgsfaktoren im Marktbericht. Um mehr zu erfahren, fordern Sie bitte einen Analystenanruf an oder geben Sie Ihre Anfrage ein.
Die wichtigste Forschungsmethodik, die vom DBMR-Forschungsteam verwendet wird, ist die Datentriangulation, die Data Mining, die Analyse der Auswirkungen von Datenvariablen auf den Markt und die primäre (Branchenexperten-)Validierung umfasst. Zu den Datenmodellen gehören ein Lieferantenpositionierungsraster, eine Marktzeitlinienanalyse, ein Marktüberblick und -leitfaden, ein Firmenpositionierungsraster, eine Patentanalyse, eine Preisanalyse, eine Firmenmarktanteilsanalyse, Messstandards, eine globale versus eine regionale und Lieferantenanteilsanalyse. Um mehr über die Forschungsmethodik zu erfahren, senden Sie eine Anfrage an unsere Branchenexperten.
Anpassung möglich
Data Bridge Market Research ist ein führendes Unternehmen in der fortgeschrittenen formativen Forschung. Wir sind stolz darauf, unseren bestehenden und neuen Kunden Daten und Analysen zu bieten, die zu ihren Zielen passen. Der Bericht kann angepasst werden, um Preistrendanalysen von Zielmarken, Marktverständnis für zusätzliche Länder (fordern Sie die Länderliste an), Daten zu klinischen Studienergebnissen, Literaturübersicht, Analysen des Marktes für aufgearbeitete Produkte und Produktbasis einzuschließen. Marktanalysen von Zielkonkurrenten können von technologiebasierten Analysen bis hin zu Marktportfoliostrategien analysiert werden. Wir können so viele Wettbewerber hinzufügen, wie Sie Daten in dem von Ihnen gewünschten Format und Datenstil benötigen. Unser Analystenteam kann Ihnen auch Daten in groben Excel-Rohdateien und Pivot-Tabellen (Fact Book) bereitstellen oder Sie bei der Erstellung von Präsentationen aus den im Bericht verfügbaren Datensätzen unterstützen.