Global Ai Training Dataset Market
Tamaño del mercado en miles de millones de dólares
Tasa de crecimiento anual compuesta (CAGR) :
% 
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 –2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
Segmentación del mercado global de conjuntos de datos de capacitación en IA, por tipo de software (herramientas de recopilación de datos, software de anotación de datos y conjuntos de datos estándar), imagen/video, audio y texto, sector vertical (TI, automoción, gobierno, atención médica, BFSI, comercio minorista y electrónico): tendencias de la industria y pronóstico hasta 2032.
Tamaño del mercado de conjuntos de datos de entrenamiento de IA
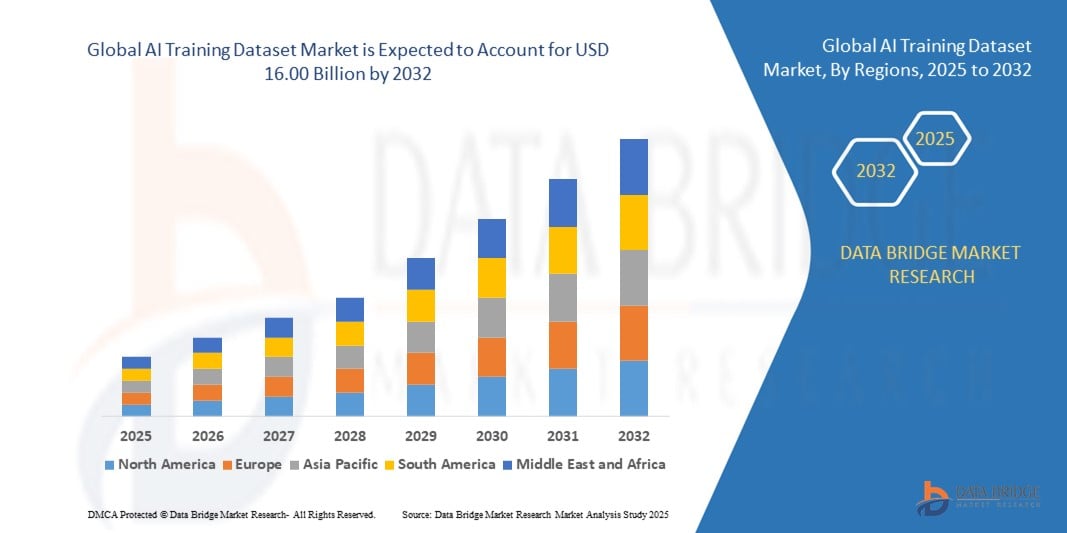
- El tamaño del mercado global de conjuntos de datos de entrenamiento de IA se valoró en USD 2,72 mil millones en 2024 y se espera que alcance los USD 16,00 mil millones para 2032 , con una CAGR del 24,80% durante el período de pronóstico.
- El crecimiento del mercado está impulsado en gran medida por la creciente adopción de tecnologías de inteligencia artificial y aprendizaje automático en sectores como la atención médica, la automoción, el comercio minorista y BFSI, lo que ha provocado un fuerte aumento de la demanda de conjuntos de datos de entrenamiento anotados y de alta calidad para mejorar la precisión y el rendimiento del modelo.
- Además, la proliferación de aplicaciones intensivas en datos (que van desde la visión artificial y el reconocimiento de voz hasta el procesamiento del lenguaje natural y el análisis predictivo) está impulsando a las organizaciones a invertir en conjuntos de datos escalables y específicos del dominio, lo que impulsa significativamente la expansión de la industria de conjuntos de datos de entrenamiento de IA.
Análisis del mercado de conjuntos de datos de entrenamiento de IA
- Los conjuntos de datos de entrenamiento de IA consisten en datos estructurados o anotados que se utilizan para entrenar modelos de aprendizaje automático en entornos de aprendizaje supervisados y semisupervisados. Estos conjuntos de datos pueden incluir imágenes, audio, vídeo, texto o entradas multimodales y son esenciales para enseñar a los sistemas de IA a reconocer patrones, realizar predicciones y automatizar decisiones con mínima intervención humana.
- El rápido auge del desarrollo de la IA está generando una demanda masiva de datos de entrenamiento, especialmente en sectores que desarrollan sistemas inteligentes para diagnóstico, detección de fraude, navegación autónoma y motores de recomendación. Como resultado, el mercado está experimentando un sólido crecimiento, impulsado por el aumento de las inversiones en servicios de anotación de datos, plataformas de datos sintéticos y ecosistemas de mercado de la IA.
- América del Norte dominó el mercado de conjuntos de datos de entrenamiento de IA con una participación del 36,3 % en 2024, debido al sólido ecosistema de IA de la región, las extensas inversiones en I+D y la presencia de importantes empresas tecnológicas y nuevas empresas de IA.
- Se espera que Asia-Pacífico sea la región de más rápido crecimiento en el mercado de conjuntos de datos de entrenamiento de IA durante el período de pronóstico debido a la rápida transformación digital, la expansión de los casos de uso de IA y el aumento del apoyo gubernamental para el desarrollo de IA en economías como China, Japón, India y Corea del Sur.
- El segmento de imagen/vídeo dominó el mercado con una cuota de mercado del 41,5 % en 2024, debido al auge de las aplicaciones de visión artificial, como la autenticación facial, la conducción autónoma, el diagnóstico médico y la vigilancia en comercios minoristas. Estos modelos requieren grandes volúmenes de imágenes y fotogramas de vídeo anotados para identificar, clasificar y rastrear objetos con alta precisión. El rápido crecimiento de los dispositivos edge y la visión integrada en drones, robótica e infraestructuras inteligentes impulsa aún más la demanda de conjuntos de datos visuales. Las organizaciones también están aprovechando cada vez más los conjuntos de datos sintéticos de imágenes y vídeos para complementar los datos del mundo real, mejorando así la robustez de los modelos en diversas condiciones ambientales.
Alcance del informe y segmentación del mercado de datos de capacitación en IA
|
Atributos |
Conjunto de datos de entrenamiento de IA: información clave del mercado |
|
Segmentos cubiertos |
|
|
Países cubiertos |
América del norte
Europa
Asia-Pacífico
Oriente Medio y África
Sudamerica
|
|
Actores clave del mercado |
|
|
Oportunidades de mercado |
|
|
Conjuntos de información de datos de valor añadido |
Además de los conocimientos del mercado, como el valor de mercado, la tasa de crecimiento, los segmentos del mercado, la cobertura geográfica, los actores del mercado y el escenario del mercado, el informe de mercado elaborado por el equipo de investigación de mercado de Data Bridge incluye un análisis en profundidad de expertos, análisis de importación/exportación, análisis de precios, análisis de consumo de producción y análisis pestle. |
Tendencias del mercado de conjuntos de datos de entrenamiento de IA
Adopción creciente de datos de entrenamiento sintéticos
- El mercado de conjuntos de datos de entrenamiento de IA está evolucionando rápidamente a medida que los datos sintéticos ganan terreno como una alternativa escalable y que cumple con la privacidad a la anotación de datos tradicionales, superando las limitaciones relacionadas con la escasez de datos, el sesgo y la exposición de información confidencial.
- Por ejemplo, empresas como NVIDIA y Mostly AI se especializan en plataformas de generación de datos sintéticos que permiten la creación de conjuntos de datos etiquetados de alta calidad para entrenar la visión artificial, el procesamiento del lenguaje natural y los sistemas autónomos en industrias como la atención médica, la automotriz y las finanzas.
- La flexibilidad de los datos sintéticos permite la creación de escenarios de eventos raros o conjuntos de datos equilibrados que mitigan el sesgo y mejoran la generalización del modelo.
- El creciente escrutinio regulatorio en torno al uso de datos personales fomenta la adopción de conjuntos de datos sintéticos que preservan la privacidad al tiempo que mantienen la utilidad analítica.
- Los avances en redes generativas antagónicas (GAN) y tecnologías de simulación facilitan muestras de datos sintéticos realistas y diversas, acelerando los ciclos de desarrollo de IA.
- Los conjuntos de datos sintéticos se integran cada vez más con conjuntos de datos del mundo real para optimizar la eficacia del entrenamiento y reducir los riesgos de sobreajuste en los modelos de aprendizaje automático.
Dinámica del mercado de conjuntos de datos de entrenamiento de IA
Conductor
Creciente demanda de conjuntos de datos multilingües y específicos de cada dominio en todas las industrias
- A medida que la adopción de IA se expande en sectores verticales como la atención médica, la automoción, el comercio minorista y las telecomunicaciones, crece la necesidad de conjuntos de datos multilingües y específicos del dominio cuidadosamente seleccionados para respaldar el entrenamiento de modelos específicos para cada idioma, contexto y tarea.
- Por ejemplo, Appen y Lionbridge proporcionan amplios conjuntos de datos anotados en distintos idiomas y dominios especializados que ayudan a las empresas a desarrollar aplicaciones de IA robustas en atención al cliente, diagnósticos médicos y vehículos autónomos adaptados a los mercados locales y entornos regulatorios.
- El aumento de la localización y personalización de productos de IA exige datos de entrenamiento contextualmente relevantes y de alta calidad para mejorar la precisión y la satisfacción del usuario. El cumplimiento normativo del sector, especialmente en salud y finanzas, exige una curación de datos adaptada al dominio, garantizando que los modelos de IA cumplan con los estándares legales y éticos.
- La creciente popularidad de la IA conversacional, el análisis de sentimientos y las herramientas de traducción de idiomas estimula la demanda de conjuntos de datos diversificados de texto, voz e imágenes en múltiples idiomas y dialectos.
- Las asociaciones estratégicas entre desarrolladores de IA y empresas de anotación de datos facilitan la creación a pedido de conjuntos de datos especializados, lo que acelera el tiempo de comercialización de las soluciones de IA.
Restricción/Desafío
Los altos costos y la demanda de tiempo de la anotación manual de datos
- La anotación manual sigue siendo un cuello de botella crítico debido a su naturaleza laboriosa, propensa a errores y costosa, y a menudo requiere expertos en el dominio y ciclos de validación prolongados que ralentizan el entrenamiento y la implementación de modelos de IA.
- Por ejemplo, las empresas que dependen del etiquetado manual para conjuntos de datos de imágenes o videos complejos, como los desarrolladores de conducción autónoma o las empresas de imágenes médicas, enfrentan altos costos operativos y desafíos de escalabilidad a pesar de los estrictos requisitos de calidad.
- La dificultad para reclutar y capacitar anotadores calificados con experiencia en el dominio exacerba los retrasos y la variabilidad en la calidad de los datos en los distintos proyectos.
- Las inconsistencias en las anotaciones y los problemas de control de calidad requieren retrabajo y procesos de revisión por niveles que incrementan el tiempo y los gastos. El aumento del tamaño de los conjuntos de datos, impulsado por los avances en la complejidad de los modelos de IA, intensifica la demanda de anotaciones, lo que sobrecarga aún más los recursos humanos y los presupuestos.
- La industria está explorando activamente herramientas de anotación semiautomatizadas y asistidas por IA para reducir los costos y el tiempo de respuesta, pero su adopción generalizada aún se ve desafiada por la confiabilidad del modelo y las complejidades de integración.
Alcance del mercado de conjuntos de datos de entrenamiento de IA
El mercado está segmentado en función del software, el tipo y la vertical.
- Por software
En cuanto al software, el mercado de conjuntos de datos para entrenamiento de IA se segmenta en herramientas de recopilación de datos, software de anotación de datos y conjuntos de datos listos para usar. El segmento de software de anotación de datos dominó el mercado en 2024 gracias a su papel fundamental en la generación de datos etiquetados de alta calidad, esenciales para el entrenamiento de modelos de aprendizaje supervisado en sectores como la automoción, la salud y el comercio minorista. Estas plataformas admiten diversos tipos de datos, como imágenes, texto, audio y vídeo, y suelen incluir funciones de anotación asistidas por IA que aceleran el proceso de etiquetado. Las empresas prefieren estas herramientas por su capacidad para gestionar grandes conjuntos de datos, facilitar la colaboración en tiempo real entre equipos distribuidos y garantizar la coherencia en las tareas de etiquetado. Su amplia integración con los procesos de aprendizaje automático y su compatibilidad con múltiples marcos de entrenamiento de modelos refuerzan aún más su dominio.
Se prevé que el segmento de conjuntos de datos listos para usar experimente la tasa de crecimiento anual compuesta (TCAC) más rápida entre 2025 y 2032, impulsado por la creciente demanda de empresas que buscan reducir el tiempo de comercialización de sus soluciones de IA. Estos conjuntos de datos preetiquetados están diseñados para dominios específicos como el reconocimiento facial, la detección de fraudes o las imágenes médicas, lo que permite a los equipos de IA omitir la laboriosa fase de recopilación de datos. Las startups y las pequeñas empresas, en particular, se benefician de su asequibilidad, velocidad y garantía de calidad. Además, a medida que la generalización de modelos se convierte en un objetivo clave, los conjuntos de datos listos para usar se buscan cada vez más para fines de evaluación comparativa y preentrenamiento, especialmente en el aprendizaje por transferencia y el desarrollo de modelos base.
- Por tipo
Según el tipo, el mercado de conjuntos de datos de entrenamiento de IA se segmenta en Imagen/Vídeo, Audio y Texto. El segmento Imagen/Vídeo representó la mayor participación, con un 41,5 %, en 2024, debido al auge de las aplicaciones de visión artificial, como la autenticación facial, la conducción autónoma, el diagnóstico médico y la vigilancia en comercios minoristas. Estos modelos requieren grandes volúmenes de imágenes y fotogramas de vídeo anotados para identificar, clasificar y rastrear objetos con alta precisión. El rápido crecimiento de los dispositivos edge y la visión integrada en drones, robótica e infraestructuras inteligentes impulsa aún más la demanda de conjuntos de datos visuales. Las organizaciones también están aprovechando cada vez más los conjuntos de datos sintéticos de imágenes y vídeos para complementar los datos del mundo real, mejorando así la robustez de los modelos en diversas condiciones ambientales.
Se prevé que el segmento de audio registre la mayor tasa de crecimiento entre 2025 y 2032, impulsado por el uso generalizado de la IA en aplicaciones de voz, como asistentes virtuales, automatización de centros de llamadas y servicios de transcripción multilingüe. Los conjuntos de datos de audio anotados con contextos de voz, eventos acústicos y ruido de fondo son fundamentales para mejorar la precisión en las tareas de reconocimiento de voz y clasificación de sonidos. El crecimiento se ve impulsado aún más por el aumento de la I+D en IA de voz con sensibilidad emocional y tecnologías de accesibilidad para personas con discapacidad visual. Ante la creciente demanda de datos de voz en idiomas y dialectos regionales, los proveedores de conjuntos de datos están ampliando su oferta para dar soporte a perfiles lingüísticos y acústicos diversificados.
- Por Vertical
Según el sector vertical, el mercado de conjuntos de datos de entrenamiento de IA se segmenta en TI, Automoción, Gobierno, Salud, BFSI, y Comercio Minorista y E-commerce. El segmento de TI lideró el mercado en 2024, gracias a las fuertes inversiones de empresas tecnológicas y proveedores de servicios en la nube en el entrenamiento de IA para ciberseguridad, automatización y mejora de la experiencia del cliente. Estas organizaciones suelen desarrollar conjuntos de datos internos o adquirir grandes volúmenes de datos estructurados y no estructurados para respaldar el desarrollo de modelos, las pruebas y el aprendizaje continuo. El rápido ritmo de la innovación de software y la integración de la IA en plataformas y servicios impulsa la demanda continua de conjuntos de datos diversos y específicos para cada tarea. Además, el acceso del sector de TI a herramientas avanzadas para el etiquetado y procesamiento de datos le permite mantener su liderazgo en el uso de conjuntos de datos.
Se proyecta que el segmento de la salud experimentará el mayor crecimiento entre 2025 y 2032, impulsado por la creciente adopción de la IA en el diagnóstico de enfermedades, el análisis de imágenes, la cirugía robótica y los sistemas de gestión de pacientes. El entrenamiento de modelos de IA en este sector requiere grandes conjuntos de datos bien procesados, como resonancias magnéticas, preparaciones patológicas, datos genómicos y notas clínicas, que deben cumplir con estrictos estándares regulatorios y éticos. El auge de las colaboraciones público-privadas, como la asociación de hospitales con empresas de IA para innovaciones basadas en datos, está impulsando la accesibilidad a los conjuntos de datos. Además, el impulso hacia una atención médica personalizada y predictiva está acelerando la demanda de datos longitudinales y multimodales de pacientes, lo que convierte a la atención médica en un sector vertical de alto crecimiento para los conjuntos de datos de entrenamiento de IA.
Análisis regional del mercado de conjuntos de datos de entrenamiento de IA
- América del Norte dominó el mercado de conjuntos de datos de entrenamiento de IA con la mayor participación en los ingresos del 36,3 % en 2024, impulsada por el sólido ecosistema de IA de la región, las amplias inversiones en I+D y la presencia de importantes empresas tecnológicas y nuevas empresas de IA.
- Las empresas de América del Norte están invirtiendo fuertemente en el entrenamiento de modelos de IA para aplicaciones en atención médica, finanzas, conducción autónoma y ciberseguridad, lo que aumenta la demanda de conjuntos de datos de entrenamiento diversos y de alta calidad.
- La región se beneficia de una infraestructura de nube avanzada, una alta alfabetización digital y un apoyo regulatorio favorable para la innovación en IA, lo que contribuye a la adquisición y el uso de conjuntos de datos a gran escala en todas las industrias.
Perspectivas del mercado de conjuntos de datos de capacitación en IA de EE. UU.
El mercado estadounidense de conjuntos de datos de entrenamiento de IA capturó la mayor participación en los ingresos en 2024 en Norteamérica, impulsado por la sólida adopción de la IA en sectores como la salud, la automoción y las TI. El rápido desarrollo de las aplicaciones de aprendizaje automático y procesamiento del lenguaje natural continúa generando demanda de datos etiquetados, especialmente en formatos de imagen, voz y texto. Tanto los gigantes tecnológicos como las startups están aprovechando volúmenes masivos de datos de entrenamiento para desarrollar modelos de IA propios. Las colaboraciones público-privadas, la investigación con respaldo gubernamental y un sector académico centrado en la innovación impulsan aún más el ecosistema de conjuntos de datos en EE. UU.
Perspectivas del mercado de conjuntos de datos de formación en IA de Europa
Se proyecta que el mercado europeo de conjuntos de datos de entrenamiento de IA crezca a una tasa de crecimiento anual compuesta (TCAC) sustancial durante el período de pronóstico, respaldado por estrictas regulaciones de privacidad de datos y un enfoque creciente en el desarrollo ético de la IA. El auge de la automatización, los servicios públicos impulsados por IA y la fabricación inteligente impulsan la demanda de conjuntos de datos de alta calidad en todo el continente. Las empresas europeas priorizan el uso de conjuntos de datos explicables e imparciales, en consonancia con el cumplimiento del RGPD y los estándares éticos. La adopción es especialmente sólida en sectores como la automoción, la sanidad y la administración pública, donde los modelos de IA entrenados con precisión son cruciales.
Perspectivas del mercado de conjuntos de datos de formación en IA del Reino Unido
Se prevé que el mercado británico de conjuntos de datos de entrenamiento de IA crezca a una tasa de crecimiento anual compuesta (TCAC) significativa durante el período de pronóstico, impulsado por iniciativas nacionales que promueven el liderazgo en IA y la transformación digital. Con las inversiones en centros de investigación de IA y la creciente demanda de automatización inteligente en sectores como la banca, la inversión y la seguridad (BFSI) y el comercio electrónico, aumenta la necesidad de conjuntos de datos fiables y preetiquetados. El dinámico ecosistema de startups del Reino Unido y la sólida presencia de proveedores de IA como servicio (IA como servicio) impulsan aún más el mercado. El énfasis en la IA responsable y el uso justo de los datos fomenta el desarrollo de conjuntos de datos de alta calidad y sin sesgos.
Perspectivas del mercado de conjuntos de datos de formación en IA de Alemania
Se prevé una expansión constante del mercado alemán de conjuntos de datos de entrenamiento de IA, impulsado por el liderazgo del país en automatización industrial, movilidad inteligente y digitalización de la atención médica. Las organizaciones alemanas adoptan cada vez más la IA en áreas como el mantenimiento predictivo, los vehículos autónomos y el diagnóstico médico, que requieren conjuntos de datos precisos y específicos para cada dominio. El mercado se beneficia de la colaboración entre instituciones de investigación, empresas e iniciativas de IA respaldadas por el gobierno. El enfoque de Alemania en la calidad, la protección de datos y la innovación respalda la demanda de soluciones de datos de entrenamiento seguras y escalables.
Perspectivas del mercado de conjuntos de datos de capacitación en IA de Asia-Pacífico
Se prevé que el mercado de conjuntos de datos de entrenamiento de IA en Asia-Pacífico crezca a la tasa de crecimiento anual compuesta (TCAC) más alta durante el período de pronóstico de 2025 a 2032, impulsado por la rápida transformación digital, la expansión de los casos de uso de la IA y el creciente apoyo gubernamental al desarrollo de la IA en economías como China, Japón, India y Corea del Sur. La proliferación de dispositivos conectados a internet, poblaciones multilingües y mercados prioritarios para dispositivos móviles está generando diversas necesidades de datos. Además, el papel de Asia-Pacífico como centro global para el talento en IA y servicios rentables de etiquetado de datos acelera aún más la producción y el consumo de conjuntos de datos en todos los sectores verticales.
Perspectivas del mercado de conjuntos de datos de capacitación en IA de Japón
El mercado japonés de conjuntos de datos de entrenamiento de IA está en constante crecimiento, impulsado por el énfasis del país en la robótica, las ciudades inteligentes y los sistemas de transporte inteligentes. La avanzada infraestructura digital de Japón y el uso generalizado de dispositivos conectados generan grandes volúmenes de datos estructurados y no estructurados. Las empresas utilizan activamente la IA para abordar la escasez de mano de obra y los desafíos del envejecimiento de la población, especialmente en los sectores de la salud y la logística. La demanda de conjuntos de datos multimodales y específicos de cada idioma aumenta a medida que la adopción de la IA se extiende a la electrónica de consumo y los servicios públicos.
Perspectivas del mercado de conjuntos de datos de capacitación en IA de China
El mercado chino de conjuntos de datos de entrenamiento de IA representó la mayor cuota de ingresos en Asia Pacífico en 2024, impulsado por la estrategia de desarrollo prioritaria de la IA, la digitalización a gran escala y el dominio del país en dispositivos inteligentes. El despliegue generalizado de sistemas de IA de reconocimiento facial, vigilancia y comercio electrónico ha generado una demanda masiva de conjuntos de datos etiquetados. Los programas respaldados por el gobierno y el auge de las empresas nacionales de IA han creado un sólido ecosistema para la generación, anotación y distribución de datos. Las prósperas iniciativas chinas de ciudades inteligentes y vehículos autónomos continúan generando grandes oportunidades para los proveedores de conjuntos de datos.
Cuota de mercado de conjuntos de datos de entrenamiento de IA
La industria de conjuntos de datos de entrenamiento de IA está liderada principalmente por empresas bien establecidas, entre las que se incluyen:
- Scale AI (EE. UU.)
- Appen (Australia)
- Lionbridge (EE. UU.)
- AWS (EE. UU.)
- Sama (EE. UU.)
- Clickworker (Reino Unido)
- Cogito Tech (EE. UU.)
- CloudFactory (Reino Unido)
- TELUS International (Canadá)
- Innodata (EE. UU.)
- iMerit (EE. UU.)
- TransPerfect (EE. UU.)
- Google (EE. UU.)
- LXT (Canadá)
- IBM (EE.UU.)
- Microsoft (EE. UU.)
- NVIDIA (EE. UU.)
Últimos avances en el mercado global de conjuntos de datos de entrenamiento de IA
- En septiembre de 2024, Innodata lanzó su Mercado de Datos de IA, lo que representa un paso significativo para abordar los desafíos de escalabilidad y accesibilidad de los datos en el entrenamiento de modelos de IA/ML. La plataforma ofrece conjuntos de datos de documentos sintéticos seleccionados y bajo demanda, que ayudan a los equipos de ciencia de datos a superar las limitaciones relacionadas con el volumen, la diversidad y la privacidad de los datos. Al simplificar el acceso a conjuntos de datos listos para usar, se espera que este mercado acelere el desarrollo de modelos de IA y satisfaga la creciente demanda de datos de entrenamiento sintéticos y específicos de cada dominio en todos los sectores.
- En septiembre de 2024, SCALE AI anunció una inversión de 21 millones de dólares en nueve proyectos de atención médica basados en IA en Canadá, en el marco de la Estrategia Pancanadiense de Inteligencia Artificial. Esta iniciativa tendrá un impacto significativo en el mercado de conjuntos de datos de entrenamiento de IA en el ámbito sanitario, al promover la colaboración entre hospitales y desarrolladores de IA. Su objetivo es mejorar la atención al paciente, reducir los tiempos de espera y optimizar las operaciones sanitarias, aumentando así la demanda de conjuntos de datos de alta calidad, de origen ético y adaptados a aplicaciones clínicas, administrativas y de diagnóstico.
- En agosto de 2024, Lionbridge Technologies, Inc. presentó Aurora AI Studio, una plataforma dedicada a ayudar a las empresas a entrenar modelos de IA con conjuntos de datos de alta calidad. Este lanzamiento responde a la creciente necesidad de datos especializados y bien anotados para respaldar casos de uso avanzados de IA. Al aprovechar la experiencia global de Lionbridge en curación y anotación de datos, la plataforma fortalece el ecosistema de IA comercial y está preparada para influir en la demanda de conjuntos de datos personalizados, multilingües y específicos de cada sector en sectores como finanzas, comercio minorista y telecomunicaciones.
- En agosto de 2024, Accenture, en colaboración con Google Cloud, aceleró la implementación de soluciones de IA generativa a través de su Centro de Excelencia en IA Generativa. Con el 45 % de los proyectos en transición a producción, esta colaboración destaca la creciente operacionalización de la IA a gran escala. Subraya la urgente necesidad de conjuntos de datos de entrenamiento seguros, diversos y listos para producción que respalden modelos avanzados de IA en las empresas. La iniciativa también integra la ciberseguridad, reforzando el papel del manejo responsable de datos y los conjuntos de datos centrados en la privacidad en la adopción de la IA empresarial.
- En julio de 2024, Microsoft Research presentó AgentInstruct, un marco de trabajo multiagente diseñado para automatizar la generación de datos sintéticos de alta calidad. Demostrado mediante mejoras en su modelo Orca-3 en diversas pruebas de referencia, este marco minimiza la intervención humana en el etiquetado de datos, lo que reduce los costes y acelera la creación de conjuntos de datos. Se espera que AgentInstruct transforme el mercado de conjuntos de datos de entrenamiento de IA al impulsar el uso de datos sintéticos para el entrenamiento de modelos a gran escala, en particular en IA generativa y modelos de base.
SKU-
Obtenga acceso en línea al informe sobre la primera nube de inteligencia de mercado del mundo
- Panel de análisis de datos interactivo
- Panel de análisis de empresas para oportunidades con alto potencial de crecimiento
- Acceso de analista de investigación para personalización y consultas
- Análisis de la competencia con panel interactivo
- Últimas noticias, actualizaciones y análisis de tendencias
- Aproveche el poder del análisis de referencia para un seguimiento integral de la competencia
Metodología de investigación
La recopilación de datos y el análisis del año base se realizan utilizando módulos de recopilación de datos con muestras de gran tamaño. La etapa incluye la obtención de información de mercado o datos relacionados a través de varias fuentes y estrategias. Incluye el examen y la planificación de todos los datos adquiridos del pasado con antelación. Asimismo, abarca el examen de las inconsistencias de información observadas en diferentes fuentes de información. Los datos de mercado se analizan y estiman utilizando modelos estadísticos y coherentes de mercado. Además, el análisis de la participación de mercado y el análisis de tendencias clave son los principales factores de éxito en el informe de mercado. Para obtener más información, solicite una llamada de un analista o envíe su consulta.
La metodología de investigación clave utilizada por el equipo de investigación de DBMR es la triangulación de datos, que implica la extracción de datos, el análisis del impacto de las variables de datos en el mercado y la validación primaria (experto en la industria). Los modelos de datos incluyen cuadrícula de posicionamiento de proveedores, análisis de línea de tiempo de mercado, descripción general y guía del mercado, cuadrícula de posicionamiento de la empresa, análisis de patentes, análisis de precios, análisis de participación de mercado de la empresa, estándares de medición, análisis global versus regional y de participación de proveedores. Para obtener más información sobre la metodología de investigación, envíe una consulta para hablar con nuestros expertos de la industria.
Personalización disponible
Data Bridge Market Research es líder en investigación formativa avanzada. Nos enorgullecemos de brindar servicios a nuestros clientes existentes y nuevos con datos y análisis que coinciden y se adaptan a sus objetivos. El informe se puede personalizar para incluir análisis de tendencias de precios de marcas objetivo, comprensión del mercado de países adicionales (solicite la lista de países), datos de resultados de ensayos clínicos, revisión de literatura, análisis de mercado renovado y base de productos. El análisis de mercado de competidores objetivo se puede analizar desde análisis basados en tecnología hasta estrategias de cartera de mercado. Podemos agregar tantos competidores sobre los que necesite datos en el formato y estilo de datos que esté buscando. Nuestro equipo de analistas también puede proporcionarle datos en archivos de Excel sin procesar, tablas dinámicas (libro de datos) o puede ayudarlo a crear presentaciones a partir de los conjuntos de datos disponibles en el informe.