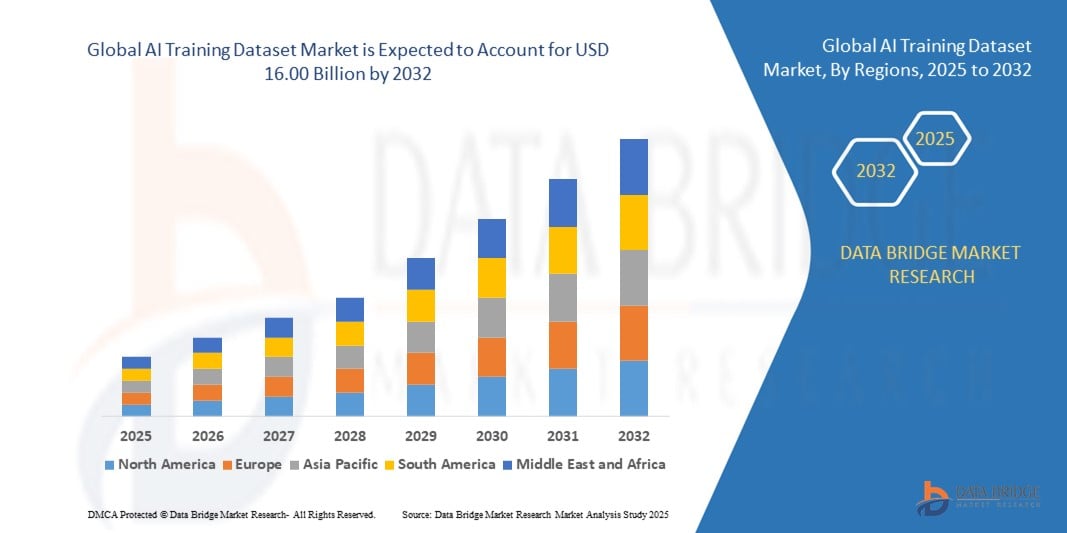
Global Ai Training Dataset Market
Taille du marché en milliards USD
TCAC :
% 
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 –2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
Segmentation du marché mondial des ensembles de données de formation à l'IA, par type de logiciel (outils de collecte de données, logiciels d'annotation de données et ensembles de données standard) (image/vidéo, audio et texte), vertical (informatique, automobile, administration publique, santé, BFSI, vente au détail et commerce électronique) - Tendances et prévisions du secteur jusqu'en 2032
Taille du marché des ensembles de données de formation à l'IA
- La taille du marché mondial des ensembles de données de formation à l'IA était évaluée à 2,72 milliards USD en 2024 et devrait atteindre 16,00 milliards USD d'ici 2032 , à un TCAC de 24,80 % au cours de la période de prévision.
- La croissance du marché est largement alimentée par l'adoption croissante des technologies d'intelligence artificielle et d'apprentissage automatique dans des secteurs tels que la santé, l'automobile, la vente au détail et le BFSI, ce qui a conduit à une forte augmentation de la demande d'ensembles de données de formation annotés de haute qualité pour améliorer la précision et les performances des modèles.
- En outre, la prolifération d’applications gourmandes en données, allant de la vision par ordinateur et de la reconnaissance vocale à la PNL et à l’analyse prédictive, incite les organisations à investir dans des ensembles de données évolutifs et spécifiques à un domaine, ce qui stimule considérablement l’expansion du secteur des ensembles de données de formation à l’IA.
Analyse du marché des ensembles de données de formation à l'IA
- Les jeux de données d'entraînement d'IA sont constitués de données structurées ou annotées utilisées pour entraîner des modèles d'apprentissage automatique dans des environnements d'apprentissage supervisé et semi-supervisé. Ces jeux de données peuvent inclure des images, des données audio, des vidéos, du texte ou des entrées multimodales et sont essentiels pour apprendre aux systèmes d'IA à reconnaître des modèles, à faire des prédictions et à automatiser les décisions avec une intervention humaine minimale.
- L'essor rapide du développement de l'IA crée une demande massive de données d'entraînement, notamment dans les secteurs développant des systèmes intelligents pour le diagnostic, la détection des fraudes, la navigation autonome et les moteurs de recommandation. En conséquence, le marché connaît une croissance robuste, soutenue par des investissements croissants dans les services d'annotation de données, les plateformes de données synthétiques et les écosystèmes de marché de l'IA.
- L'Amérique du Nord a dominé le marché des ensembles de données de formation en IA avec une part de 36,3 % en 2024, en raison du solide écosystème d'IA de la région, des investissements importants en R&D et de la présence de grandes entreprises technologiques et de startups d'IA.
- L'Asie-Pacifique devrait être la région connaissant la croissance la plus rapide sur le marché des ensembles de données de formation à l'IA au cours de la période de prévision en raison de la transformation numérique rapide, de l'expansion des cas d'utilisation de l'IA et du soutien croissant du gouvernement au développement de l'IA dans des économies telles que la Chine, le Japon, l'Inde et la Corée du Sud.
- Le segment image/vidéo a dominé le marché avec une part de marché de 41,5 % en 2024, grâce à l'explosion des applications de vision par ordinateur telles que l'authentification faciale, la conduite autonome, le diagnostic médical et la surveillance commerciale. Ces modèles nécessitent d'importants volumes d'images annotées et d'images vidéo pour identifier, classer et suivre les objets avec une grande précision. La croissance rapide des dispositifs périphériques et de la vision intégrée aux drones, à la robotique et aux infrastructures intelligentes alimente la demande en jeux de données visuelles. Les entreprises exploitent également de plus en plus les jeux de données d'images et de vidéos de synthèse pour compléter les données réelles, améliorant ainsi la robustesse des modèles dans des conditions environnementales variées.
Portée du rapport et segmentation du marché des ensembles de données de formation à l'IA
|
Attributs |
Informations clés sur le marché des ensembles de données de formation à l'IA |
|
Segments couverts |
|
|
Pays couverts |
Amérique du Nord
Europe
Asie-Pacifique
Moyen-Orient et Afrique
Amérique du Sud
|
|
Acteurs clés du marché |
|
|
Opportunités de marché |
|
|
Ensembles d'informations de données à valeur ajoutée |
Outre les informations sur le marché telles que la valeur marchande, le taux de croissance, les segments de marché, la couverture géographique, les acteurs du marché et le scénario du marché, le rapport de marché organisé par l'équipe de recherche sur le marché de Data Bridge comprend une analyse approfondie des experts, une analyse des importations/exportations, une analyse des prix, une analyse de la consommation de production et une analyse du pilon. |
Tendances du marché des ensembles de données de formation à l'IA
Adoption croissante des données de formation synthétiques
- Le marché des ensembles de données de formation à l'IA évolue rapidement à mesure que les données synthétiques gagnent du terrain en tant qu'alternative évolutive et conforme à la confidentialité à l'annotation de données traditionnelle, surmontant les limitations liées à la rareté des données, aux biais et à l'exposition des informations sensibles.
- Par exemple, des entreprises telles que NVIDIA et Mostly AI se spécialisent dans les plateformes de génération de données synthétiques qui permettent la création d'ensembles de données étiquetés de haute qualité pour la formation de la vision par ordinateur, du traitement du langage naturel et des systèmes autonomes dans des secteurs tels que la santé, l'automobile et la finance.
- La flexibilité des données synthétiques permet la création de scénarios d'événements rares ou d'ensembles de données équilibrés atténuant les biais et améliorant la généralisation du modèle
- Le contrôle réglementaire croissant autour de l'utilisation des données personnelles encourage l'adoption d'ensembles de données synthétiques qui préservent la confidentialité tout en maintenant l'utilité analytique
- Les progrès des réseaux antagonistes génératifs (GAN) et des technologies de simulation facilitent la création d'échantillons de données synthétiques réalistes et diversifiés, accélérant ainsi les cycles de développement de l'IA.
- Les ensembles de données synthétiques sont de plus en plus intégrés aux ensembles de données du monde réel pour optimiser l'efficacité de la formation et réduire les risques de surapprentissage dans les modèles d'apprentissage automatique.
Dynamique du marché des ensembles de données de formation à l'IA
Conducteur
Demande croissante d'ensembles de données spécifiques à un domaine et multilingues dans tous les secteurs
- Avec l'adoption croissante de l'IA dans des secteurs verticaux tels que la santé, l'automobile, la vente au détail et les télécommunications, le besoin d'ensembles de données multilingues et spécifiques à un domaine, soigneusement organisés, augmente pour prendre en charge la formation de modèles spécifiques à la langue, au contexte et aux tâches.
- Par exemple, Appen et Lionbridge fournissent de vastes ensembles de données annotées dans plusieurs langues et domaines spécialisés, aidant les entreprises à développer des applications d'IA robustes dans le service client, les diagnostics médicaux et les véhicules autonomes adaptés aux marchés locaux et aux environnements réglementaires.
- La localisation et la personnalisation croissantes des produits d'IA exigent des données d'entraînement de haute qualité et contextuellement pertinentes pour améliorer la précision et la satisfaction des utilisateurs. La conformité réglementaire du secteur, notamment dans les secteurs de la santé et de la finance, impose une curation des données adaptée au domaine, garantissant ainsi le respect des normes légales et éthiques des modèles d'IA.
- La popularité croissante de l'IA conversationnelle, de l'analyse des sentiments et des outils de traduction linguistique stimule la demande d'ensembles de données de texte, de parole et d'image diversifiés dans plusieurs langues et dialectes.
- Les partenariats stratégiques entre les développeurs d'IA et les sociétés d'annotation de données facilitent la création à la demande d'ensembles de données spécialisés, accélérant ainsi la mise sur le marché des solutions d'IA.
Retenue/Défi
Coûts élevés et temps considérable de l'annotation manuelle des données
- L'annotation manuelle reste un goulot d'étranglement critique en raison de sa nature laborieuse, sujette aux erreurs et coûteuse, nécessitant souvent des experts du domaine et de longs cycles de validation qui ralentissent la formation et le déploiement des modèles d'IA.
- Par exemple, les entreprises qui s'appuient sur l'étiquetage manuel pour des ensembles de données d'images ou de vidéos complexes, comme les développeurs de véhicules autonomes ou les sociétés d'imagerie médicale, sont confrontées à des coûts opérationnels élevés et à des défis d'évolutivité malgré des exigences de qualité strictes.
- La difficulté de recruter et de former des annotateurs qualifiés possédant une expertise dans le domaine aggrave les retards et la variabilité de la qualité des données entre les projets.
- Les incohérences d'annotation et les problèmes de contrôle qualité nécessitent des remaniements et des processus de révision multicouches, ce qui augmente les délais et les coûts. La croissance de la taille des ensembles de données, due aux progrès de la complexité des modèles d'IA, intensifie la demande d'annotations, sollicitant encore davantage les ressources humaines et les budgets.
- L'industrie explore activement les outils d'annotation semi-automatisés et assistés par l'IA pour réduire les coûts et les délais d'exécution, mais leur adoption à grande échelle est toujours entravée par la fiabilité des modèles et les complexités d'intégration.
Portée du marché des ensembles de données de formation à l'IA
Le marché est segmenté en fonction du logiciel, du type et du secteur vertical.
- Par logiciel
Du point de vue des logiciels, le marché des jeux de données d'entraînement de l'IA est segmenté en outils de collecte de données, logiciels d'annotation de données et jeux de données prêts à l'emploi. Le segment des logiciels d'annotation de données a dominé le marché en 2024, grâce à son rôle essentiel dans la génération de données étiquetées de haute qualité, essentielles à l'entraînement de modèles d'apprentissage supervisé dans des secteurs tels que l'automobile, la santé et la vente au détail. Ces plateformes prennent en charge divers types de données, notamment les images, le texte, l'audio et la vidéo, et sont souvent équipées de fonctionnalités d'annotation assistée par l'IA qui accélèrent le processus d'étiquetage. Les entreprises privilégient ces outils pour leur capacité à gérer de grands ensembles de données, à permettre la collaboration en temps réel entre équipes dispersées et à garantir la cohérence des tâches d'étiquetage. Leur intégration étendue aux pipelines de machine learning et leur compatibilité avec de multiples cadres d'entraînement de modèles renforcent encore leur domination.
Le segment des jeux de données prêts à l'emploi devrait connaître le TCAC le plus rapide entre 2025 et 2032, porté par la demande croissante des entreprises souhaitant réduire les délais de mise sur le marché de leurs solutions d'IA. Ces jeux de données pré-étiquetés sont conçus pour des domaines spécifiques tels que la reconnaissance faciale, la détection des fraudes ou l'imagerie médicale, permettant aux équipes d'IA d'éviter la fastidieuse phase de collecte de données. Les startups et les petites entreprises, en particulier, bénéficient de leur accessibilité, de leur rapidité et de leur garantie qualité. De plus, la généralisation des modèles devenant un enjeu majeur, les jeux de données prêts à l'emploi sont de plus en plus recherchés à des fins d'analyse comparative et de pré-apprentissage, notamment pour l'apprentissage par transfert et le développement de modèles fondamentaux.
- Par type
En fonction du type, le marché des jeux de données d'entraînement en IA est segmenté en images/vidéos, audio et texte. Le segment image/vidéo représentait la part la plus importante (41,5 %) en 2024, grâce à l'explosion des applications de vision par ordinateur telles que l'authentification faciale, la conduite autonome, les diagnostics médicaux et la surveillance commerciale. Ces modèles nécessitent d'importants volumes d'images annotées et de trames vidéo pour identifier, classer et suivre les objets avec une grande précision. La croissance rapide des appareils périphériques et de la vision intégrée aux drones, à la robotique et aux infrastructures intelligentes alimente la demande de jeux de données visuelles. Les entreprises exploitent également de plus en plus les jeux de données d'images et de vidéos de synthèse pour compléter les données réelles, améliorant ainsi la robustesse des modèles dans des conditions environnementales variées.
Le segment audio devrait enregistrer sa plus forte croissance entre 2025 et 2032, grâce à l'utilisation généralisée de l'IA dans les applications vocales, notamment les assistants virtuels, l'automatisation des centres d'appels et les services de transcription multilingue. Les jeux de données audio annotés, incluant la parole, les événements acoustiques et les contextes de bruit de fond, sont essentiels pour améliorer la précision des tâches de reconnaissance vocale et de classification des sons. La croissance est encore accélérée par l'intensification de la R&D dans l'IA vocale émotionnellement consciente et les technologies d'accessibilité pour les malvoyants. Face à la demande croissante de données vocales dans les langues et dialectes régionaux, les fournisseurs de jeux de données élargissent leurs offres pour prendre en charge des profils linguistiques et acoustiques diversifiés.
- Par Vertical
Sur le plan vertical, le marché des jeux de données d'entraînement à l'IA est segmenté en IT, Automobile, Administration publique, Santé, BFSI, et Retail & E-commerce. Le segment IT a dominé le marché en 2024, les entreprises technologiques et les fournisseurs de services cloud investissant massivement dans l'entraînement à l'IA pour la cybersécurité, l'automatisation et l'amélioration de l'expérience client. Ces organisations développent souvent des jeux de données en interne ou acquièrent d'importants volumes de données structurées et non structurées pour soutenir le développement de modèles, les tests et l'apprentissage continu. Le rythme rapide de l'innovation logicielle et de l'intégration de l'IA sur les plateformes et les services alimente une demande constante de jeux de données diversifiés et spécifiques à chaque tâche. De plus, l'accès du secteur IT à des outils avancés d'étiquetage et de traitement des données lui permet de conserver son leadership dans l'utilisation des jeux de données.
Le secteur de la santé devrait connaître la croissance la plus rapide entre 2025 et 2032, portée par l'adoption croissante de l'IA dans le diagnostic des maladies, l'analyse d'imagerie, la chirurgie robotique et les systèmes de gestion des patients. L'entraînement des modèles d'IA dans ce secteur nécessite des ensembles de données volumineux et soigneusement organisés, tels que des IRM, des lames de pathologie, des données génomiques et des dossiers cliniques, qui doivent respecter des normes réglementaires et éthiques strictes. L'essor des collaborations public-privé, notamment les partenariats entre hôpitaux et entreprises d'IA pour des innovations axées sur les données, améliore l'accessibilité des données. De plus, la demande croissante de soins de santé personnalisés et prédictifs accélère la demande de données patients longitudinales et multimodales, faisant de la santé un secteur à forte croissance pour les ensembles de données d'entraînement de l'IA.
Analyse régionale du marché des ensembles de données de formation à l'IA
- L'Amérique du Nord a dominé le marché des ensembles de données de formation en IA avec la plus grande part de revenus de 36,3 % en 2024, grâce au solide écosystème d'IA de la région, à d'importants investissements en R&D et à la présence de grandes entreprises technologiques et de startups d'IA.
- Les entreprises d'Amérique du Nord investissent massivement dans la formation de modèles d'IA pour des applications dans les domaines de la santé, de la finance, de la conduite autonome et de la cybersécurité, augmentant ainsi la demande d'ensembles de données de formation diversifiés et de haute qualité.
- La région bénéficie d'une infrastructure cloud avancée, d'une grande culture numérique et d'un soutien réglementaire favorable à l'innovation en matière d'IA, contribuant ainsi à l'approvisionnement et à l'utilisation d'ensembles de données à grande échelle dans tous les secteurs.
Aperçu du marché américain des ensembles de données de formation à l'IA
Le marché américain des bases de données d'entraînement à l'IA a représenté la plus grande part de chiffre d'affaires en 2024 en Amérique du Nord, grâce à une adoption massive de l'IA dans des secteurs tels que la santé, l'automobile et l'informatique. Le développement rapide des applications d'apprentissage automatique et de traitement du langage naturel continue de générer une demande de données étiquetées, notamment sous forme d'images, de parole et de texte. Géants de la technologie et startups exploitent des volumes massifs de données d'entraînement pour développer des modèles d'IA propriétaires. Les partenariats public-privé, la recherche soutenue par l'État et un secteur universitaire axé sur l'innovation dynamisent encore l'écosystème des bases de données aux États-Unis.
Aperçu du marché européen des ensembles de données de formation à l'IA
Le marché européen des jeux de données d'entraînement à l'IA devrait connaître une croissance annuelle moyenne (TCAC) substantielle au cours de la période de prévision, soutenue par des réglementations strictes en matière de confidentialité des données et une attention croissante portée au développement éthique de l'IA. L'essor de l'automatisation, les services publics axés sur l'IA et la fabrication intelligente stimulent la demande de jeux de données de haute qualité sur tout le continent. Les entreprises européennes privilégient l'utilisation de jeux de données explicables et impartiaux, conformes au RGPD et aux normes éthiques. L'adoption est particulièrement forte dans des secteurs tels que l'automobile, la santé et le secteur public, où des modèles d'IA entraînés avec précision sont essentiels.
Aperçu du marché britannique des ensembles de données de formation à l'IA
Le marché britannique des bases de données d'entraînement à l'IA devrait connaître une croissance annuelle moyenne (TCAC) significative au cours de la période de prévision, stimulé par les initiatives nationales promouvant le leadership en IA et la transformation numérique. Avec les investissements dans les pôles de recherche en IA et la demande croissante d'automatisation intelligente dans des secteurs tels que le BFSI et le e-commerce, le besoin de bases de données fiables et pré-étiquetées augmente. Le dynamisme de l'écosystème des startups britanniques et la forte présence des fournisseurs d'IA en tant que service (IA-as-a-service) renforcent encore le marché. L'accent mis sur une IA responsable et une utilisation équitable des données encourage le développement de bases de données de haute qualité et impartiales.
Aperçu du marché allemand des ensembles de données de formation à l'IA
Le marché allemand des bases de données d'entraînement à l'IA devrait connaître une croissance constante, porté par le leadership du pays en matière d'automatisation industrielle, de mobilité intelligente et de numérisation des soins de santé. Les entreprises allemandes adoptent de plus en plus l'IA dans des domaines tels que la maintenance prédictive, les véhicules autonomes et le diagnostic médical, qui nécessitent tous des bases de données précises et spécifiques. Ce marché bénéficie de la collaboration entre les instituts de recherche, les entreprises et les initiatives d'IA soutenues par le gouvernement. L'accent mis par l'Allemagne sur la qualité, la protection des données et l'innovation soutient la demande de solutions de données d'entraînement sécurisées et évolutives.
Aperçu du marché des ensembles de données de formation à l'IA en Asie-Pacifique
Le marché des bases de données d'entraînement à l'IA en Asie-Pacifique devrait connaître sa croissance annuelle moyenne la plus rapide entre 2025 et 2032, porté par la transformation numérique rapide, l'expansion des cas d'utilisation de l'IA et le soutien accru des gouvernements au développement de l'IA dans des économies comme la Chine, le Japon, l'Inde et la Corée du Sud. La prolifération des appareils connectés, le multilinguisme des populations et la priorité donnée au mobile créent des besoins diversifiés en matière de données. De plus, le rôle de la région Asie-Pacifique en tant que pôle mondial de talents en IA et de services d'étiquetage de données rentables accélère encore la production et la consommation de bases de données dans tous les secteurs.
Aperçu du marché japonais des données de formation à l'IA
Le marché japonais des bases de données d'entraînement à l'IA connaît une croissance constante, portée par l'importance accordée par le pays à la robotique, aux villes intelligentes et aux systèmes de transport intelligents. L'infrastructure numérique ultra-moderne du Japon et la généralisation des appareils connectés génèrent d'importants volumes de données structurées et non structurées. Les entreprises utilisent activement l'IA pour répondre aux pénuries de main-d'œuvre et aux défis liés au vieillissement de la population, notamment dans les secteurs de la santé et de la logistique. La demande de bases de données multimodales et linguistiques spécifiques augmente à mesure que l'adoption de l'IA se développe dans l'électronique grand public et les services publics.
Aperçu du marché chinois des données de formation à l'IA
Le marché chinois des jeux de données d'entraînement à l'IA représentait la plus grande part de revenus en Asie-Pacifique en 2024, grâce à la stratégie de développement de l'IA, à la numérisation à grande échelle et à la domination du pays sur les appareils intelligents. Le déploiement généralisé des systèmes d'IA pour la reconnaissance faciale, la surveillance et le commerce électronique a généré une demande massive de jeux de données étiquetés. Les programmes soutenus par le gouvernement et l'essor des entreprises nationales d'IA ont créé un écosystème robuste pour la génération, l'annotation et la distribution de données. Les initiatives florissantes de la Chine en matière de villes intelligentes et de véhicules autonomes continuent d'offrir de vastes opportunités aux fournisseurs de jeux de données.
Part de marché des ensembles de données de formation à l'IA
L'industrie des ensembles de données de formation à l'IA est principalement dirigée par des entreprises bien établies, notamment :
- Scale AI (États-Unis)
- Appen (Australie)
- Lionbridge (États-Unis)
- AWS (États-Unis)
- Sama (États-Unis)
- Clickworker (Royaume-Uni)
- Cogito Tech (États-Unis)
- CloudFactory (Royaume-Uni)
- TELUS International (Canada)
- Innodata (États-Unis)
- iMerit (États-Unis)
- TransPerfect (États-Unis)
- Google (États-Unis)
- LXT (Canada)
- IBM (États-Unis)
- Microsoft (États-Unis)
- NVIDIA (États-Unis)
Derniers développements sur le marché mondial des bases de données de formation à l'IA
- En septembre 2024, Innodata a lancé sa place de marché de données d'IA, marquant une étape importante pour répondre aux défis d'évolutivité et d'accessibilité des données dans l'entraînement des modèles d'IA/ML. La plateforme propose des jeux de données synthétiques organisés et à la demande, qui aident les équipes de data science à surmonter les contraintes liées au volume, à la diversité et à la confidentialité des données. En simplifiant l'accès à des jeux de données prêts à l'emploi, cette place de marché devrait accélérer le développement de modèles d'IA et répondre à la demande croissante de données d'entraînement synthétiques et spécifiques à chaque domaine dans tous les secteurs.
- En septembre 2024, SCALE AI a annoncé un investissement de 21 millions de dollars dans neuf projets de soins de santé axés sur l'IA au Canada, dans le cadre de la Stratégie pancanadienne en matière d'intelligence artificielle. Cette initiative devrait avoir un impact significatif sur le marché des bases de données d'entraînement en IA dans le domaine de la santé en favorisant la collaboration entre les hôpitaux et les développeurs d'IA. Elle vise à améliorer les soins aux patients, à réduire les temps d'attente et à optimiser les opérations de santé, augmentant ainsi la demande pour des bases de données de haute qualité, issues de sources éthiques et adaptées aux applications cliniques, administratives et diagnostiques.
- En août 2024, Lionbridge Technologies, Inc. a lancé Aurora AI Studio, une plateforme dédiée destinée à aider les entreprises à former des modèles d'IA à partir de jeux de données de haute qualité. Ce lancement répond au besoin croissant de données spécialisées et bien annotées pour soutenir les cas d'utilisation avancés de l'IA. En s'appuyant sur l'expertise mondiale de Lionbridge en matière de curation et d'annotation de données, la plateforme renforce l'écosystème de l'IA commerciale et est en mesure d'influencer la demande de jeux de données personnalisés, multilingues et sectoriels dans des secteurs tels que la finance, la distribution et les télécommunications.
- En août 2024, Accenture, en partenariat avec Google Cloud, a accéléré le déploiement de solutions d'IA générative grâce à son Centre d'excellence en IA générative. Avec 45 % des projets en phase de production, cette collaboration met en évidence l'opérationnalisation croissante de l'IA à grande échelle. Elle souligne le besoin urgent de jeux de données d'entraînement sécurisés, diversifiés et prêts pour la production, prenant en charge les modèles d'IA avancés dans toutes les entreprises. L'initiative intègre également la cybersécurité, renforçant ainsi le rôle d'une gestion responsable des données et de jeux de données respectueux de la confidentialité dans l'adoption de l'IA en entreprise.
- En juillet 2024, Microsoft Research a dévoilé AgentInstruct, un framework de workflow multi-agents conçu pour automatiser la génération de données synthétiques de haute qualité. Démontré par les améliorations apportées à son modèle Orca-3 lors de différents tests de performance, ce framework minimise l'intervention humaine dans l'étiquetage des données, réduisant ainsi les coûts et accélérant la création des jeux de données. AgentInstruct devrait révolutionner le marché des jeux de données d'entraînement en IA en faisant progresser l'utilisation des données synthétiques pour l'entraînement de modèles à grande échelle, notamment pour l'IA générative et les modèles fondamentaux.
SKU-
Accédez en ligne au rapport sur le premier cloud mondial de veille économique
- Tableau de bord d'analyse de données interactif
- Tableau de bord d'analyse d'entreprise pour les opportunités à fort potentiel de croissance
- Accès d'analyste de recherche pour la personnalisation et les requêtes
- Analyse de la concurrence avec tableau de bord interactif
- Dernières actualités, mises à jour et analyse des tendances
- Exploitez la puissance de l'analyse comparative pour un suivi complet de la concurrence
Méthodologie de recherche
La collecte de données et l'analyse de l'année de base sont effectuées à l'aide de modules de collecte de données avec des échantillons de grande taille. L'étape consiste à obtenir des informations sur le marché ou des données connexes via diverses sources et stratégies. Elle comprend l'examen et la planification à l'avance de toutes les données acquises dans le passé. Elle englobe également l'examen des incohérences d'informations observées dans différentes sources d'informations. Les données de marché sont analysées et estimées à l'aide de modèles statistiques et cohérents de marché. De plus, l'analyse des parts de marché et l'analyse des tendances clés sont les principaux facteurs de succès du rapport de marché. Pour en savoir plus, veuillez demander un appel d'analyste ou déposer votre demande.
La méthodologie de recherche clé utilisée par l'équipe de recherche DBMR est la triangulation des données qui implique l'exploration de données, l'analyse de l'impact des variables de données sur le marché et la validation primaire (expert du secteur). Les modèles de données incluent la grille de positionnement des fournisseurs, l'analyse de la chronologie du marché, l'aperçu et le guide du marché, la grille de positionnement des entreprises, l'analyse des brevets, l'analyse des prix, l'analyse des parts de marché des entreprises, les normes de mesure, l'analyse globale par rapport à l'analyse régionale et des parts des fournisseurs. Pour en savoir plus sur la méthodologie de recherche, envoyez une demande pour parler à nos experts du secteur.
Personnalisation disponible
Data Bridge Market Research est un leader de la recherche formative avancée. Nous sommes fiers de fournir à nos clients existants et nouveaux des données et des analyses qui correspondent à leurs objectifs. Le rapport peut être personnalisé pour inclure une analyse des tendances des prix des marques cibles, une compréhension du marché pour d'autres pays (demandez la liste des pays), des données sur les résultats des essais cliniques, une revue de la littérature, une analyse du marché des produits remis à neuf et de la base de produits. L'analyse du marché des concurrents cibles peut être analysée à partir d'une analyse basée sur la technologie jusqu'à des stratégies de portefeuille de marché. Nous pouvons ajouter autant de concurrents que vous le souhaitez, dans le format et le style de données que vous recherchez. Notre équipe d'analystes peut également vous fournir des données sous forme de fichiers Excel bruts, de tableaux croisés dynamiques (Fact book) ou peut vous aider à créer des présentations à partir des ensembles de données disponibles dans le rapport.