世界のAIトレーニングデータセット市場規模、シェア、トレンド分析レポート
Market Size in USD Billion
CAGR :
% 
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 –2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
世界のAIトレーニングデータセット市場セグメンテーション、ソフトウェア(データ収集ツール、データ注釈ソフトウェア、既製データセット)、タイプ(画像/ビデオ、オーディオ、テキスト)、垂直(IT、自動車、政府、ヘルスケア、BFSI、小売およびEコマース)別 - 2032年までの業界動向と予測
AIトレーニングデータセット市場規模
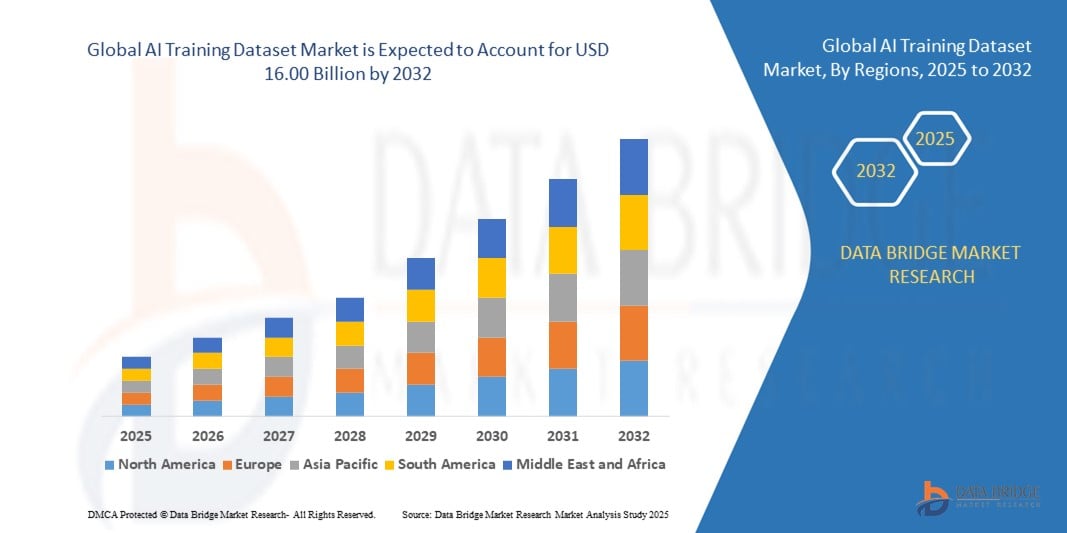
- 世界のAIトレーニングデータセット市場規模は2024年に27億2000万米ドルと評価され、予測期間中に24.80%のCAGRで成長し、2032年には160億米ドルに達すると予想されています。
- 市場の成長は、ヘルスケア、自動車、小売、BFSIなどの分野での人工知能と機械学習技術の採用の増加に大きく牽引されており、モデルの精度とパフォーマンスを向上させるための高品質で注釈付きのトレーニングデータセットの需要が急増しています。
- さらに、コンピュータービジョンや音声認識からNLPや予測分析に至るまで、データ集約型アプリケーションの急増により、組織はスケーラブルでドメイン固有のデータセットに投資するようになり、AIトレーニングデータセット業界の拡大が大幅に促進されています。
AIトレーニングデータセット市場分析
- AIトレーニングデータセットは、教師あり学習および半教師あり学習環境における機械学習モデルのトレーニングに使用される構造化データまたは注釈付きデータで構成されています。これらのデータセットには、画像、音声、動画、テキスト、またはマルチモーダル入力が含まれる場合があり、パターン認識、予測、そして人間の介入を最小限に抑えた意思決定の自動化をAIシステムに学習させるために不可欠です。
- AI開発の急速な進展は、特に診断、不正検知、自律航行、レコメンデーションエンジンといったインテリジェントシステムの開発分野において、学習データに対する膨大な需要を生み出しています。その結果、データアノテーションサービス、合成データプラットフォーム、AIマーケットプレイスエコシステムへの投資増加に支えられ、市場は力強い成長を遂げています。
- 北米は、強力なAIエコシステム、大規模な研究開発投資、大手テクノロジー企業やAIスタートアップの存在により、2024年にはAIトレーニングデータセット市場で36.3%のシェアを獲得し、市場を席巻した。
- アジア太平洋地域は、急速なデジタル変革、AIユースケースの拡大、中国、日本、インド、韓国などの経済圏におけるAI開発に対する政府の支援の増加により、予測期間中にAIトレーニングデータセット市場で最も急速に成長する地域になると予想されています。
- 顔認証、自動運転、医療診断、小売監視といったコンピュータービジョンアプリケーションの爆発的な増加により、画像/動画セグメントは2024年に41.5%の市場シェアを獲得し、市場を席巻しました。これらのモデルでは、物体を高精度に識別、分類、追跡するために、膨大な量の注釈付き画像と動画フレームが必要です。ドローン、ロボット工学、スマートインフラにおけるエッジデバイスや組み込みビジョンの急速な成長は、ビジュアルデータセットの需要をさらに高めています。また、実世界のデータを補完するために合成画像や動画データセットを活用し、さまざまな環境条件下でのモデルの堅牢性を向上させる組織も増えています。
レポートの範囲とAIトレーニングデータセット市場のセグメンテーション
|
属性 |
AIトレーニングデータセットの主要市場インサイト |
|
対象セグメント |
|
|
対象国 |
北米
ヨーロッパ
アジア太平洋
中東およびアフリカ
南アメリカ
|
|
主要な市場プレーヤー |
|
|
市場機会 |
|
|
付加価値データ情報セット |
データブリッジ市場調査チームがまとめた市場レポートには、市場価値、成長率、市場セグメント、地理的範囲、市場プレーヤー、市場シナリオなどの市場洞察に加えて、専門家による詳細な分析、輸入/輸出分析、価格分析、生産消費分析、乳棒分析が含まれています。 |
AIトレーニングデータセット市場の動向
合成トレーニングデータの採用拡大
- AIトレーニングデータセット市場は、従来のデータ注釈に代わるスケーラブルでプライバシーに準拠した代替手段として合成データが普及し、データの不足、バイアス、機密情報の露出に関連する制限を克服するにつれて、急速に進化しています。
- 例えば、NVIDIAやMostly AIなどの企業は、医療、自動車、金融などの業界でコンピュータービジョン、自然言語処理、自律システムをトレーニングするための高品質のラベル付きデータセットの作成を可能にする合成データ生成プラットフォームに特化しています。
- 合成データの柔軟性により、まれなイベントのシナリオや、バイアスを軽減し、モデルの一般化を強化するバランスの取れたデータセットの作成が可能になります。
- 個人データの使用に関する規制の強化により、分析の有用性を維持しながらプライバシーを保護する合成データセットの採用が促進される。
- 生成的敵対ネットワーク(GAN)とシミュレーション技術の進歩により、現実的で多様な合成データサンプルが可能になり、AI開発サイクルが加速します。
- 合成データセットは、トレーニングの有効性を最適化し、機械学習モデルの過剰適合リスクを軽減するために、現実世界のデータセットとますます統合されています。
AIトレーニングデータセット市場の動向
ドライバ
業界全体でドメイン固有および多言語データセットの需要が増加
- AIの導入が医療、自動車、小売、通信などの分野で拡大するにつれ、言語、コンテキスト、タスク固有のモデルトレーニングをサポートするために、綿密にキュレーションされたドメイン固有の多言語データセットの必要性が高まっています。
- 例えば、AppenとLionbridgeは、言語や専門分野をまたいで広範な注釈付きデータセットを提供し、企業が顧客サービス、医療診断、自律走行車などの地域市場や規制環境に合わせた堅牢なAIアプリケーションを開発できるよう支援しています。
- AI製品のローカライゼーションとパーソナライゼーションの進展に伴い、精度とユーザー満足度を向上させるには、高品質で文脈に即した学習データが必要です。特に医療と金融の分野における業界規制の遵守は、AIモデルが法的および倫理的基準を満たすことを保証する、ドメインを考慮したデータキュレーションを義務付けています。
- 会話型AI、感情分析、言語翻訳ツールの人気の高まりにより、複数の言語や方言の多様なテキスト、音声、画像データセットの需要が高まっています。
- AI開発者とデータアノテーション企業との戦略的パートナーシップにより、専門的なデータセットのオンデマンド作成が容易になり、AIソリューションの市場投入までの時間が短縮されます。
抑制/挑戦
手作業によるデータ注釈作成の高コストと時間集約
- 手動によるアノテーションは、労働集約的で、エラーが発生しやすく、費用がかかるため、依然として重大なボトルネックであり、多くの場合、ドメイン専門家と長い検証サイクルが必要となり、AIモデルのトレーニングと展開が遅くなります。
- 例えば、自動運転開発者や医療用画像処理会社など、複雑な画像や動画データセットの手動ラベル付けに依存している企業は、厳格な品質要件にもかかわらず、高い運用コストと拡張性の課題に直面しています。
- ドメイン専門知識を持つ熟練したアノテーターの採用とトレーニングの難しさにより、プロジェクト間の遅延とデータ品質のばらつきが悪化します。
- アノテーションの不一致や品質管理上の問題により、手直しや階層化されたレビュープロセスが必要となり、時間と費用が増加します。AIモデルの複雑化に伴うデータセットの規模の拡大は、アノテーションの需要を増大させ、人的資源と予算をさらに圧迫しています。
- 業界では、コストとターンアラウンドタイムを削減するために、半自動およびAI支援のアノテーションツールを積極的に検討していますが、モデルの信頼性と統合の複雑さにより、広範な導入には依然として課題があります。
AIトレーニングデータセット市場の展望
市場は、ソフトウェア、タイプ、垂直に基づいてセグメント化されています。
- ソフトウェア別
AIトレーニングデータセット市場は、ソフトウェアに基づいて、データ収集ツール、データアノテーションソフトウェア、および既製データセットに分類されます。データアノテーションソフトウェアセグメントは、自動車、ヘルスケア、小売などの分野における教師あり学習モデルのトレーニングに不可欠な、高品質のラベル付きデータを生成する上で重要な役割を果たしているため、2024年には市場を席巻しました。これらのプラットフォームは、画像、テキスト、音声、動画など、さまざまなデータタイプをサポートし、ラベル付けプロセスを高速化するAI支援アノテーション機能を備えている場合が多くあります。企業は、大規模なデータセットの処理能力、分散チーム間のリアルタイムコラボレーションの実現、ラベル付けタスクの一貫性の確保を理由に、これらのツールを好んでいます。機械学習パイプラインとの広範な統合と、複数のモデルトレーニングフレームワークとの互換性も、その優位性をさらに強化しています。
既製データセットセグメントは、AIソリューションの市場投入までの期間短縮を目指す企業からの需要の高まりを背景に、2025年から2032年にかけて最も高いCAGRを達成すると予想されています。これらのラベル付きデータセットは、顔認識、不正検出、医用画像といった特定の分野向けにキュレーションされており、AIチームは時間のかかるデータ収集フェーズを省略できます。特にスタートアップ企業や中小企業は、その手頃な価格、スピード、そして品質保証の恩恵を受けています。さらに、モデルの一般化が重要な焦点となるにつれ、既製データセットは、特に転移学習や基盤モデル開発において、ベンチマークや事前学習の目的でますます求められています。
- タイプ別
AIトレーニングデータセット市場は、種類別に画像/動画、音声、テキストに分類されます。顔認証、自動運転、医療診断、小売監視といったコンピュータービジョンアプリケーションの爆発的な増加により、画像/動画セグメントは2024年に41.5%と最大のシェアを占めました。これらのモデルでは、物体を高精度に識別、分類、追跡するために、膨大な量の注釈付き画像と動画フレームが必要です。ドローン、ロボット工学、スマートインフラにおけるエッジデバイスと組み込みビジョンの急速な成長は、ビジュアルデータセットの需要をさらに高めています。また、企業は実世界のデータを補完するために合成画像や動画データセットを活用し、さまざまな環境条件下でのモデルの堅牢性を向上させるケースが増えています。
音声セグメントは、バーチャルアシスタント、コールセンター自動化、多言語文字起こしサービスといった音声駆動型アプリケーションにおけるAIの普及に支えられ、2025年から2032年にかけて最も高い成長率を記録すると予想されています。音声、音響イベント、背景ノイズのコンテキストをアノテーションした音声データセットは、音声認識および音声分類タスクの精度向上に不可欠です。感情認識音声AIや視覚障害者向けアクセシビリティ技術の研究開発の増加により、成長はさらに加速します。地域言語や方言の音声データに対する需要が高まる中、データセットプロバイダーは多様な言語および音響プロファイルをサポートするためにサービスを拡大しています。
- 垂直方向
AIトレーニングデータセット市場は、業種別に見ると、IT、自動車、政府機関、ヘルスケア、BFSI、小売・Eコマースに分類されます。2024年には、テクノロジー企業やクラウドサービスプロバイダーがサイバーセキュリティ、自動化、顧客体験向上のためのAIトレーニングに多額の投資を行ったため、ITセグメントが市場を牽引しました。これらの組織は、モデル開発、テスト、継続的な学習を支援するために、自社でデータセットを開発したり、大量の構造化データおよび非構造化データを調達したりすることがよくあります。プラットフォームやサービス間でのソフトウェアイノベーションとAI統合の急速な進展は、多様でタスク固有のデータセットに対する継続的な需要を促進しています。さらに、ITセクターはデータのラベリングと処理のための高度なツールへのアクセスが可能であるため、データセット活用におけるリーダーシップを維持しています。
ヘルスケア分野は、疾患診断、画像解析、ロボット手術、患者管理システムにおけるAI導入の増加に牽引され、2025年から2032年にかけて最も急速な成長が見込まれています。この分野におけるAIモデルのトレーニングには、MRIスキャン、病理スライド、ゲノムデータ、臨床記録など、大規模かつ厳選されたデータセットが必要であり、厳格な規制および倫理基準を遵守する必要があります。病院がAI企業と提携してデータ駆動型イノベーションを推進するなど、官民連携の増加により、データセットへのアクセス性が向上しています。さらに、パーソナライズされた予測医療への取り組みが、縦断的かつマルチモーダルな患者データへの需要を加速させており、ヘルスケアはAIトレーニングデータセットの急成長分野となっています。
AIトレーニングデータセット市場の地域分析
- 北米は、強力なAIエコシステム、大規模な研究開発投資、大手テクノロジー企業やAIスタートアップの存在により、2024年には36.3%という最大の収益シェアでAIトレーニングデータセット市場を席巻しました。
- 北米の企業は、ヘルスケア、金融、自動運転、サイバーセキュリティなどのアプリケーション向けのAIモデルのトレーニングに多額の投資を行っており、多様で高品質なトレーニングデータセットの需要が高まっています。
- この地域は、高度なクラウドインフラストラクチャ、高いデジタルリテラシー、AIイノベーションに対する有利な規制支援の恩恵を受けており、業界全体にわたる大規模なデータセットの調達と利用に貢献しています。
米国AIトレーニングデータセット市場インサイト
米国のAIトレーニングデータセット市場は、ヘルスケア、自動車、ITなどの業界におけるAIの堅調な導入を背景に、2024年に北米で最大の収益シェアを獲得しました。機械学習および自然言語処理アプリケーションの急速な発展は、特に画像、音声、テキスト形式のラベル付きデータに対する需要を継続的に生み出しています。テクノロジー大手企業もスタートアップ企業も、膨大な量のトレーニングデータを活用して独自のAIモデルを開発しています。官民パートナーシップ、政府支援の研究、そしてイノベーションに重点を置く学術セクターは、米国のデータセットエコシステムをさらに加速させています。
ヨーロッパのAIトレーニングデータセット市場インサイト
欧州のAIトレーニングデータセット市場は、厳格なデータプライバシー規制と倫理的なAI開発への関心の高まりを背景に、予測期間中に大幅なCAGRで成長すると予測されています。自動化、AIを活用した公共サービス、スマート製造の台頭は、欧州全域で高品質なデータセットの需要を押し上げています。欧州企業は、GDPRの遵守と倫理基準に準拠し、説明可能で偏りのないデータセットの活用を重視しています。特に、精密にトレーニングされたAIモデルが不可欠な自動車、ヘルスケア、政府機関などの分野では、導入が顕著です。
英国のAIトレーニングデータセット市場に関する洞察
英国のAIトレーニングデータセット市場は、AIリーダーシップとデジタルトランスフォーメーションを促進する国家的な取り組みに後押しされ、予測期間中に大幅なCAGRで成長すると予想されています。AI研究ハブへの投資や、銀行・金融サービス(BFSI)やeコマースといった分野におけるインテリジェントオートメーションの需要の高まりを受け、信頼性の高いラベル付きデータセットの需要が高まっています。英国の活気あるスタートアップエコシステムと、AI-as-a-Serviceプロバイダーの強力な存在感も、この市場をさらに活性化させています。責任あるAIと公正なデータ利用への重点は、高品質でバイアスのないデータセットの開発を促進しています。
ドイツAIトレーニングデータセット市場インサイト
ドイツのAIトレーニングデータセット市場は、産業オートメーション、スマートモビリティ、ヘルスケアのデジタル化における同国のリーダーシップに牽引され、着実に拡大すると予想されています。ドイツの組織は、予測保守、自律走行車、医療診断などの分野でAIの導入を拡大しており、これらの分野ではいずれも正確で分野固有のデータセットが求められます。市場は、研究機関、企業、そして政府支援のAIイニシアチブとの連携によって恩恵を受けています。ドイツは品質、データ保護、そしてイノベーションを重視しており、安全でスケーラブルなトレーニングデータソリューションの需要を支えています。
アジア太平洋地域のAIトレーニングデータセット市場に関する洞察
アジア太平洋地域のAIトレーニングデータセット市場は、急速なデジタルトランスフォーメーション、AIユースケースの拡大、そして中国、日本、インド、韓国などの経済圏におけるAI開発に対する政府支援の強化を背景に、2025年から2032年の予測期間中に最も高いCAGRで成長すると予想されています。インターネット接続デバイスの普及、多言語人口、そしてモバイルファースト市場の拡大は、多様なデータニーズを生み出しています。さらに、アジア太平洋地域はAI人材と費用対効果の高いデータラベリングサービスのグローバルハブとしての役割を果たしており、あらゆる業種におけるデータセットの生産と消費をさらに加速させています。
日本AIトレーニングデータセット市場インサイト
日本のAIトレーニングデータセット市場は、ロボット工学、スマートシティ、高度道路交通システム(ITS)への注力に支えられ、着実に成長しています。日本の高度なデジタルインフラとコネクテッドデバイスの普及により、大量の構造化データと非構造化データが生成されています。企業は、特に医療と物流の分野で、人手不足と高齢化の課題に対処するためにAIを積極的に活用しています。AIの導入が家電製品や公共サービスに拡大するにつれ、マルチモーダルで言語に特化したデータセットの需要が高まっています。
中国AIトレーニングデータセット市場インサイト
中国のAIトレーニングデータセット市場は、2024年にアジア太平洋地域最大の収益シェアを占めました。これは、同国のAIファースト開発戦略、大規模なデジタル化、そしてスマートデバイスの優位性に牽引されています。顔認識、監視、eコマースAIシステムの普及により、ラベル付きデータセットへの需要が急増しています。政府支援プログラムと国内AI企業の台頭により、データ生成、アノテーション、配信のための堅牢なエコシステムが形成されています。中国で活発に展開されているスマートシティと自動運転車の取り組みは、データセットプロバイダーにとって大きなビジネスチャンスを生み出し続けています。
AIトレーニングデータセットの市場シェア
AI トレーニング データセット業界は、主に次のような定評のある企業によって主導されています。
- スケールAI(米国)
- アッペン(オーストラリア)
- ライオンブリッジ(米国)
- AWS(米国)
- サマ(米国)
- クリックワーカー(英国)
- コギトテック(米国)
- クラウドファクトリー(英国)
- TELUS International(カナダ)
- イノデータ(米国)
- iMerit(米国)
- トランスパーフェクト(米国)
- Google(米国)
- LXT(カナダ)
- IBM(米国)
- マイクロソフト(米国)
- NVIDIA(米国)
世界のAIトレーニングデータセット市場の最新動向
- 2024年9月、InnodataはAIデータマーケットプレイスを立ち上げ、AI/MLモデルのトレーニングにおけるデータのスケーラビリティとアクセシビリティの課題解決に向けた重要な一歩を踏み出しました。このプラットフォームは、キュレーションされたオンデマンドの合成ドキュメントデータセットを提供し、データサイエンスチームがデータ量、多様性、プライバシーに関する制限を克服するのに役立ちます。すぐに使用できるデータセットへのアクセスを簡素化することで、このマーケットプレイスはAIモデル開発を加速し、業界全体で高まる合成データとドメイン固有のトレーニングデータの需要に対応することが期待されています。
- SCALE AIは2024年9月、全カナダ人工知能戦略に基づき、カナダ全土のAI活用医療プロジェクト9件に2,100万ドルを投資すると発表しました。この取り組みは、病院とAI開発者の連携を促進することで、医療分野におけるAIトレーニングデータセット市場に大きな影響を与えると予想されます。患者ケアの向上、待ち時間の短縮、医療業務の最適化を目指しており、臨床、管理、診断アプリケーション向けにカスタマイズされた、高品質で倫理的に提供されたデータセットの需要を高めることが期待されます。
- 2024年8月、Lionbridge Technologies, Inc.は、高品質なデータセットを用いたAIモデルの学習を支援する専用プラットフォーム「Aurora AI Studio」を発表しました。このリリースは、高度なAIユースケースをサポートするために、専門的で適切にアノテーションされたデータに対する需要の高まりに対応します。Lionbridgeのデータキュレーションとアノテーションに関するグローバルな専門知識を活用することで、このプラットフォームは商用AIエコシステムを強化し、金融、小売、通信などの分野において、カスタマイズ可能で多言語対応、業界固有のデータセットに対する需要に影響を与えることが期待されます。
- 2024年8月、アクセンチュアはGoogle Cloudと提携し、Generative AI Center of Excellenceを通じてGenerative AIソリューションの導入を加速させました。プロジェクトの45%が本番環境に移行しており、この協業はAIの大規模な運用化の進展を浮き彫りにしています。これは、企業全体の高度なAIモデルを支える、安全で多様性に富み、本番環境対応可能なトレーニングデータセットの緊急の必要性を浮き彫りにしています。この取り組みはサイバーセキュリティも統合し、企業のAI導入における責任あるデータ処理とプライバシー重視のデータセットの役割を強化しています。
- 2024年7月、Microsoft Researchは、高品質な合成データの生成を自動化するために設計されたマルチエージェントワークフローフレームワーク「AgentInstruct」を発表しました。様々なベンチマークにおけるOrca-3モデルの改良を通して実証されたこのフレームワークは、データのラベル付けにおける人間の介入を最小限に抑え、コストを削減し、データセット作成を加速します。AgentInstructは、特に生成AIや基盤モデルにおいて、大規模モデルのトレーニングにおける合成データの活用を促進することで、AIトレーニングデータセット市場を再構築すると期待されています。
SKU-
世界初のマーケットインテリジェンスクラウドに関するレポートにオンラインでアクセスする
- インタラクティブなデータ分析ダッシュボード
- 成長の可能性が高い機会のための企業分析ダッシュボード
- カスタマイズとクエリのためのリサーチアナリストアクセス
- インタラクティブなダッシュボードによる競合分析
- 最新ニュース、更新情報、トレンド分析
- 包括的な競合追跡のためのベンチマーク分析のパワーを活用
調査方法
データ収集と基準年分析は、大規模なサンプル サイズのデータ収集モジュールを使用して行われます。この段階では、さまざまなソースと戦略を通じて市場情報または関連データを取得します。過去に取得したすべてのデータを事前に調査および計画することも含まれます。また、さまざまな情報ソース間で見られる情報の不一致の調査も含まれます。市場データは、市場統計モデルと一貫性モデルを使用して分析および推定されます。また、市場シェア分析と主要トレンド分析は、市場レポートの主要な成功要因です。詳細については、アナリストへの電話をリクエストするか、お問い合わせをドロップダウンしてください。
DBMR 調査チームが使用する主要な調査方法は、データ マイニング、データ変数が市場に与える影響の分析、および一次 (業界の専門家) 検証を含むデータ三角測量です。データ モデルには、ベンダー ポジショニング グリッド、市場タイムライン分析、市場概要とガイド、企業ポジショニング グリッド、特許分析、価格分析、企業市場シェア分析、測定基準、グローバルと地域、ベンダー シェア分析が含まれます。調査方法について詳しくは、お問い合わせフォームから当社の業界専門家にご相談ください。
カスタマイズ可能
Data Bridge Market Research は、高度な形成的調査のリーダーです。当社は、既存および新規のお客様に、お客様の目標に合致し、それに適したデータと分析を提供することに誇りを持っています。レポートは、対象ブランドの価格動向分析、追加国の市場理解 (国のリストをお問い合わせください)、臨床試験結果データ、文献レビュー、リファービッシュ市場および製品ベース分析を含めるようにカスタマイズできます。対象競合他社の市場分析は、技術ベースの分析から市場ポートフォリオ戦略まで分析できます。必要な競合他社のデータを、必要な形式とデータ スタイルでいくつでも追加できます。当社のアナリスト チームは、粗い生の Excel ファイル ピボット テーブル (ファクト ブック) でデータを提供したり、レポートで利用可能なデータ セットからプレゼンテーションを作成するお手伝いをしたりすることもできます。