Global Ai Training Dataset Market
Размер рынка в млрд долларов США
CAGR :
% 
 USD
2.72 Billion
USD
16.00 Billion
2024
2032
USD
2.72 Billion
USD
16.00 Billion
2024
2032
| 2025 –2032 | |
| USD 2.72 Billion | |
| USD 16.00 Billion | |
| % | |
|
Сегментация мирового рынка наборов данных для обучения ИИ по типу программного обеспечения (инструменты сбора данных, ПО для аннотации данных и готовые наборы данных) (изображения/видео, аудио и текст), вертикали (ИТ, автомобилестроение, государственный сектор, здравоохранение, бизнес-финансирование, розничная торговля и электронная коммерция) — отраслевые тенденции и прогноз до 2032 года
Размер рынка наборов данных для обучения ИИ
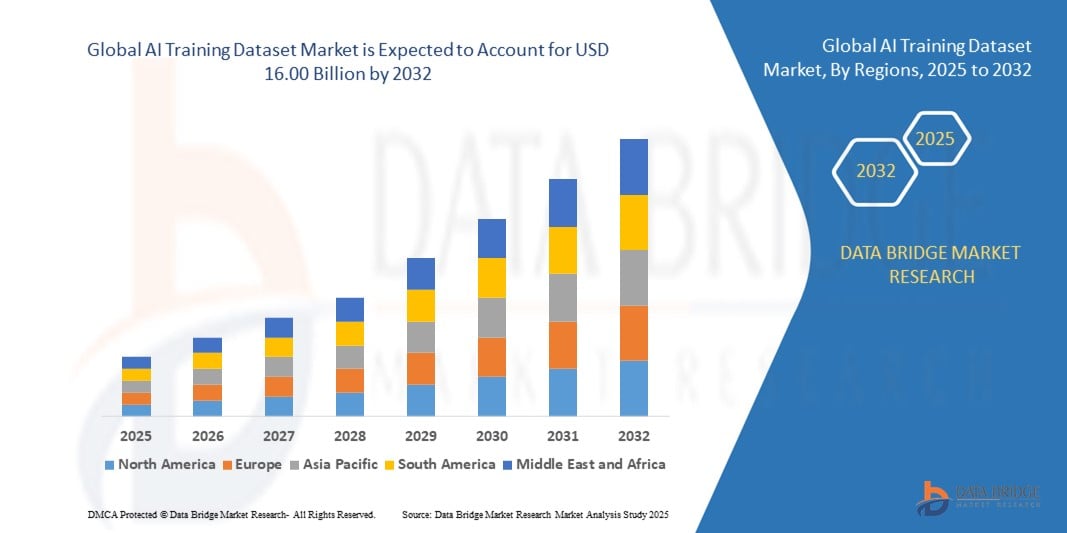
- Объем мирового рынка наборов данных для обучения искусственного интеллекта в 2024 году оценивался в 2,72 млрд долларов США , а к 2032 году , как ожидается, он достигнет 16 млрд долларов США при среднегодовом темпе роста 24,80% в прогнозируемый период.
- Рост рынка во многом обусловлен растущим внедрением технологий искусственного интеллекта и машинного обучения в таких секторах, как здравоохранение, автомобилестроение, розничная торговля и BFSI, что привело к резкому увеличению спроса на высококачественные аннотированные обучающие наборы данных для повышения точности и производительности моделей.
- Более того, распространение приложений, работающих с большими объемами данных, — от компьютерного зрения и распознавания речи до обработки естественного языка и предиктивной аналитики — побуждает организации инвестировать в масштабируемые, предметно-ориентированные наборы данных, что значительно ускоряет расширение отрасли наборов данных для обучения ИИ.
Анализ рынка наборов данных для обучения ИИ
- Наборы данных для обучения ИИ состоят из структурированных или аннотированных данных, используемых для обучения моделей машинного обучения в контролируемых и полуконтролируемых средах. Эти наборы данных могут включать изображения, аудио, видео, текст или мультимодальные входные данные и необходимы для обучения систем ИИ распознаванию закономерностей, построению прогнозов и автоматизации принятия решений с минимальным вмешательством человека.
- Стремительный рост развития ИИ создаёт огромный спрос на данные для обучения, особенно в секторах, разрабатывающих интеллектуальные системы для диагностики, обнаружения мошенничества, автономной навигации и рекомендательных систем. В результате рынок демонстрирует устойчивый рост, поддерживаемый растущими инвестициями в сервисы аннотации данных, платформы синтетических данных и экосистемы рынка ИИ.
- Северная Америка доминировала на рынке наборов данных для обучения ИИ с долей 36,3% в 2024 году благодаря мощной экосистеме ИИ в регионе, масштабным инвестициям в НИОКР и присутствию крупных технологических компаний и стартапов в области ИИ.
- Ожидается, что Азиатско-Тихоокеанский регион станет самым быстрорастущим регионом на рынке наборов данных для обучения ИИ в течение прогнозируемого периода благодаря быстрой цифровой трансформации, расширению вариантов использования ИИ и увеличению государственной поддержки развития ИИ в таких странах, как Китай, Япония, Индия и Южная Корея.
- Сегмент изображений и видео доминировал на рынке с долей 41,5% в 2024 году благодаря бурному развитию приложений компьютерного зрения, таких как аутентификация по лицу, автономное вождение, медицинская диагностика и видеонаблюдение в розничной торговле. Эти модели требуют огромных объемов аннотированных изображений и видеокадров для высокоточной идентификации, классификации и отслеживания объектов. Стремительный рост числа периферийных устройств и встроенных систем машинного зрения в дронах, робототехнике и интеллектуальной инфраструктуре дополнительно стимулирует спрос на визуальные наборы данных. Организации также все чаще используют синтетические наборы изображений и видеоданных для дополнения данных реального мира, повышая надежность моделей в различных условиях окружающей среды.
Область применения отчета и сегментация рынка наборов данных для обучения ИИ
|
Атрибуты |
Ключевые рыночные данные для обучения ИИ |
|
Охваченные сегменты |
|
|
Страны действия |
Северная Америка
Европа
Азиатско-Тихоокеанский регион
Ближний Восток и Африка
Южная Америка
|
|
Ключевые игроки рынка |
|
|
Рыночные возможности |
|
|
Информационные наборы данных с добавленной стоимостью |
Помимо таких рыночных данных, как рыночная стоимость, темпы роста, сегменты рынка, географический охват, участники рынка и рыночный сценарий, отчет о рынке, подготовленный командой Data Bridge Market Research, включает в себя углубленный экспертный анализ, анализ импорта/экспорта, анализ цен, анализ потребления продукции и анализ пестицидов. |
Тенденции рынка наборов данных для обучения ИИ
Растущее внедрение синтетических обучающих данных
- Рынок наборов данных для обучения искусственного интеллекта стремительно развивается, поскольку синтетические данные набирают популярность как масштабируемая, соответствующая требованиям конфиденциальности альтернатива традиционному аннотированию данных, преодолевая ограничения, связанные с нехваткой данных, предвзятостью и раскрытием конфиденциальной информации.
- Например, такие компании, как NVIDIA и Mostly AI, специализируются на платформах генерации синтетических данных, которые позволяют создавать высококачественные маркированные наборы данных для обучения компьютерному зрению, обработке естественного языка и автономным системам в таких отраслях, как здравоохранение, автомобилестроение и финансы.
- Гибкость синтетических данных позволяет создавать сценарии редких событий или сбалансированные наборы данных, уменьшая смещение и улучшая обобщение модели.
- Усиление контроля со стороны регулирующих органов за использованием персональных данных стимулирует внедрение синтетических наборов данных, которые обеспечивают конфиденциальность и при этом сохраняют аналитическую ценность.
- Достижения в области генеративно-состязательных сетей (GAN) и технологий моделирования способствуют созданию реалистичных и разнообразных синтетических выборок данных, ускоряя циклы разработки ИИ.
- Синтетические наборы данных все чаще интегрируются с реальными наборами данных для оптимизации эффективности обучения и снижения рисков переобучения в моделях машинного обучения.
Динамика рынка наборов данных для обучения ИИ
Водитель
Растущий спрос на предметно-ориентированные и многоязычные наборы данных в различных отраслях
- С расширением использования ИИ в таких отраслях, как здравоохранение, автомобилестроение, розничная торговля и телекоммуникации, растет потребность в тщательно отобранных предметно-ориентированных и многоязычных наборах данных для поддержки обучения моделей с учетом языка, контекста и конкретных задач.
- Например, Appen и Lionbridge предоставляют обширные аннотированные наборы данных по разным языкам и специализированным областям, помогая предприятиям разрабатывать надежные приложения ИИ в сфере обслуживания клиентов, медицинской диагностики и автономных транспортных средств, адаптированные к местным рынкам и нормативно-правовой среде.
- Растущая локализация и персонализация продуктов ИИ требует высококачественных, контекстно-релевантных обучающих данных для повышения точности и удовлетворенности пользователей. Соблюдение отраслевых норм, особенно в здравоохранении и финансах, требует отбора данных с учетом специфики предметной области, что гарантирует соответствие моделей ИИ юридическим и этическим стандартам.
- Растущая популярность разговорного ИИ, анализа настроений и инструментов языкового перевода стимулирует спрос на разнообразные наборы текстовых, речевых и графических данных на разных языках и диалектах.
- Стратегическое партнерство между разработчиками ИИ и компаниями, занимающимися аннотацией данных, способствует созданию специализированных наборов данных по запросу, ускоряя вывод решений ИИ на рынок.
Сдержанность/Вызов
Высокие затраты и время на ручную аннотацию данных
- Ручное аннотирование остается критически важным узким местом из-за его трудоемкости, подверженности ошибкам и дороговизны, часто требуя привлечения экспертов в предметной области и длительных циклов проверки, что замедляет обучение и развертывание модели ИИ.
- Например, предприятия, использующие ручную маркировку для сложных наборов изображений или видеоданных, такие как разработчики беспилотных автомобилей или компании, занимающиеся медицинской визуализацией, сталкиваются с высокими эксплуатационными расходами и проблемами масштабируемости, несмотря на строгие требования к качеству.
- Сложность набора и обучения квалифицированных аннотаторов, обладающих экспертными знаниями в данной области, усугубляет задержки и изменчивость качества данных в разных проектах.
- Несоответствия в аннотациях и проблемы контроля качества требуют доработки и многоуровневых процессов проверки, что увеличивает время и расходы. Рост объёмов наборов данных, обусловленный ростом сложности моделей ИИ, повышает спрос на аннотации, что ещё больше увеличивает нагрузку на человеческие ресурсы и бюджеты.
- Отрасль активно изучает полуавтоматические и основанные на искусственном интеллекте инструменты аннотации для сокращения затрат и времени выполнения, но их широкому внедрению по-прежнему препятствуют надежность моделей и сложность интеграции.
Рынок наборов данных для обучения ИИ
Рынок сегментирован по признаку программного обеспечения, типа и вертикали.
- По программному обеспечению
На основе программного обеспечения рынок наборов данных для обучения ИИ сегментируется на инструменты сбора данных, программное обеспечение для аннотации данных и готовые наборы данных. Сегмент программного обеспечения для аннотации данных доминировал на рынке в 2024 году благодаря своей критической роли в создании высококачественных размеченных данных, необходимых для обучения моделей контролируемого обучения в таких секторах, как автомобилестроение, здравоохранение и розничная торговля. Эти платформы поддерживают различные типы данных, включая изображения, текст, аудио и видео, и часто оснащены функциями аннотации с помощью ИИ, которые ускоряют процесс маркировки. Предприятия предпочитают эти инструменты за их способность обрабатывать большие наборы данных, обеспечивать совместную работу распределенных команд в режиме реального времени и обеспечивать согласованность задач маркировки. Их широкая интеграция с конвейерами машинного обучения и совместимость с несколькими фреймворками обучения моделей еще больше укрепляют их доминирование.
Ожидается, что сегмент готовых наборов данных будет демонстрировать самые высокие среднегодовые темпы роста в период с 2025 по 2032 год, что обусловлено растущим спросом со стороны компаний, стремящихся сократить сроки вывода на рынок своих ИИ-решений. Эти предварительно размеченные наборы данных предназначены для конкретных областей, таких как распознавание лиц, выявление мошенничества или медицинская визуализация, что позволяет командам, работающим с ИИ, избегать трудоемкого этапа сбора данных. Стартапы и малые предприятия, в частности, выигрывают от их доступности, скорости и гарантии качества. Кроме того, поскольку обобщение моделей становится ключевым направлением, готовые наборы данных все чаще востребованы для бенчмаркинга и предварительного обучения, особенно в области трансферного обучения и разработки базовых моделей.
- По типу
По типу рынок наборов данных для обучения ИИ сегментируется на сегменты «Изображения/Видео», «Аудио» и «Текст». На сегмент «Изображения/Видео» в 2024 году пришлась наибольшая доля – 41,5% – благодаря бурному развитию приложений компьютерного зрения, таких как аутентификация по лицу, автономное вождение, медицинская диагностика и видеонаблюдение в розничной торговле. Эти модели требуют огромных объёмов аннотированных изображений и видеокадров для высокоточной идентификации, классификации и отслеживания объектов. Стремительный рост числа периферийных устройств и встроенных систем машинного зрения в дронах, робототехнике и интеллектуальной инфраструктуре дополнительно стимулирует спрос на наборы визуальных данных. Организации также всё чаще используют наборы синтетических изображений и видеоданных для дополнения данных реального мира, повышая надёжность моделей в различных условиях окружающей среды.
Ожидается, что сегмент аудио будет демонстрировать самые высокие темпы роста в период с 2025 по 2032 год, чему будет способствовать широкое использование ИИ в голосовых приложениях, включая виртуальных помощников, автоматизацию колл-центров и многоязычные сервисы транскрипции. Аннотированные аудиоданные с речевыми, акустическими событиями и фоновым шумом критически важны для повышения точности распознавания речи и классификации звуков. Росту также способствует расширение исследований и разработок в области эмоционально-чувствительного голосового ИИ и технологий доступности для слабовидящих. В связи с растущим спросом на голосовые данные на региональных языках и диалектах поставщики наборов данных расширяют свои предложения для поддержки различных лингвистических и акустических профилей.
- По вертикали
По вертикали рынок наборов данных для обучения ИИ сегментируется на следующие сферы: ИТ, автомобилестроение, государственный сектор, здравоохранение, бизнес-финансирование, розничная торговля и электронная коммерция. В 2024 году ИТ-сегмент лидировал на рынке, поскольку технологические компании и поставщики облачных услуг активно инвестируют в обучение ИИ для обеспечения кибербезопасности, автоматизации и улучшения качества обслуживания клиентов. Эти организации часто разрабатывают собственные наборы данных или закупают огромные объёмы структурированных и неструктурированных данных для разработки моделей, тестирования и непрерывного обучения. Стремительные темпы инноваций в области программного обеспечения и интеграции ИИ между платформами и сервисами стимулируют постоянный спрос на разнообразные наборы данных, ориентированные на конкретные задачи. Более того, доступ ИТ-сектора к передовым инструментам для маркировки и обработки данных позволяет ему сохранять лидерство в использовании наборов данных.
Прогнозируется, что сегмент здравоохранения будет демонстрировать самые быстрые темпы роста в период с 2025 по 2032 год, что обусловлено растущим внедрением ИИ в диагностику заболеваний, анализ изображений, роботизированную хирургию и системы управления пациентами. Обучение моделей ИИ в этом секторе требует больших, тщательно подобранных наборов данных, таких как МРТ-снимки, патологические препараты, геномные данные и клинические записи, которые должны соответствовать строгим нормативным и этическим стандартам. Расширение государственно-частного сотрудничества, например, сотрудничество больниц с компаниями, разрабатывающими ИИ, для создания инноваций на основе данных, повышает доступность данных. Кроме того, стремление к персонализированной и предиктивной медицине ускоряет спрос на продольные и мультимодальные данные о пациентах, что делает здравоохранение высокорастущей вертикалью для обучения ИИ.
Региональный анализ рынка наборов данных для обучения ИИ
- Северная Америка доминировала на рынке наборов данных для обучения ИИ с наибольшей долей выручки в 36,3% в 2024 году, что обусловлено мощной экосистемой ИИ в регионе, масштабными инвестициями в НИОКР и присутствием крупных технологических компаний и стартапов в области ИИ.
- Предприятия в Северной Америке активно инвестируют в обучение моделей ИИ для приложений в здравоохранении, финансах, автономном вождении и кибербезопасности, тем самым увеличивая спрос на разнообразные и высококачественные наборы данных для обучения.
- Регион получает выгоду от развитой облачной инфраструктуры, высокой цифровой грамотности и благоприятной нормативной поддержки инноваций в области ИИ, что способствует масштабному приобретению и использованию наборов данных в различных отраслях.
Обзор рынка наборов данных для обучения искусственного интеллекта в США
Рынок обучающих наборов данных для ИИ в США в 2024 году занял наибольшую долю выручки в Северной Америке благодаря активному внедрению ИИ в таких отраслях, как здравоохранение, автомобилестроение и ИТ. Стремительное развитие приложений машинного обучения и обработки естественного языка продолжает генерировать спрос на размеченные данные, особенно в форматах изображений, речи и текста. Технологические гиганты и стартапы используют огромные объемы обучающих данных для разработки собственных моделей ИИ. Государственно-частное партнерство, поддерживаемые государством исследования и инновационно-ориентированный академический сектор дополнительно ускоряют развитие экосистемы наборов данных в США.
Обзор европейского рынка наборов данных для обучения искусственному интеллекту
Ожидается, что европейский рынок наборов данных для обучения ИИ будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, чему будут способствовать строгие правила конфиденциальности данных и растущее внимание к этичному развитию ИИ. Рост автоматизации, развитие государственных услуг на основе ИИ и интеллектуального производства обуславливают спрос на высококачественные наборы данных по всему континенту. Европейские предприятия делают акцент на использовании объяснимых и объективных наборов данных, соответствующих требованиям GDPR и этическим стандартам. Особенно активное внедрение наблюдается в таких секторах, как автомобилестроение, здравоохранение и государственный сектор, где высокоточные модели ИИ имеют решающее значение.
Обзор рынка наборов данных для обучения искусственному интеллекту в Великобритании
Ожидается, что рынок наборов данных для обучения ИИ в Великобритании будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, чему будут способствовать национальные инициативы, продвигающие лидерство в области ИИ и цифровую трансформацию. Инвестиции в исследовательские центры ИИ и растущий спрос на интеллектуальную автоматизацию в таких секторах, как бизнес-финансирование, финансовая и финансовая деятельность (BFSI) и электронная коммерция, приводят к увеличению потребности в надежных, предварительно маркированных наборах данных. Активная экосистема стартапов в Великобритании и сильное присутствие поставщиков услуг ИИ дополнительно укрепляют рынок. Акцент на ответственном подходе к ИИ и справедливом использовании данных стимулирует разработку высококачественных, непредвзятых наборов данных.
Обзор рынка наборов данных для обучения ИИ в Германии
Ожидается, что рынок наборов данных для обучения с использованием ИИ в Германии будет стабильно расти, чему способствует лидерство страны в области промышленной автоматизации, интеллектуальной мобильности и цифровизации здравоохранения. Немецкие организации всё чаще внедряют ИИ в таких областях, как предиктивное техническое обслуживание, автономные транспортные средства и медицинская диагностика, требующих точных и предметно-ориентированных наборов данных. Рынок выигрывает от сотрудничества между исследовательскими институтами, корпорациями и государственными инициативами в области ИИ. Внимание Германии к качеству, защите данных и инновациям поддерживает спрос на безопасные и масштабируемые решения для обучения с использованием данных.
Обзор рынка наборов данных для обучения ИИ в Азиатско-Тихоокеанском регионе
Ожидается, что рынок наборов данных для обучения ИИ в Азиатско-Тихоокеанском регионе будет расти самыми быстрыми среднегодовыми темпами в прогнозируемый период с 2025 по 2032 год благодаря быстрой цифровой трансформации, расширению сфер применения ИИ и усилению государственной поддержки развития ИИ в таких странах, как Китай, Япония, Индия и Южная Корея. Распространение устройств, подключенных к интернету, многоязычное население и рынки, ориентированные в первую очередь на мобильные устройства, создают разнообразные потребности в данных. Кроме того, роль Азиатско-Тихоокеанского региона как глобального центра для специалистов в области ИИ и экономически эффективных сервисов маркировки данных дополнительно ускоряет создание и потребление наборов данных во всех отраслях.
Обзор рынка наборов данных для обучения ИИ в Японии
Рынок наборов данных для обучения на основе ИИ в Японии стабильно растёт, чему способствует акцент страны на робототехнике, умных городах и интеллектуальных транспортных системах. Высокоразвитая цифровая инфраструктура Японии и широкое использование подключённых устройств генерируют большие объёмы структурированных и неструктурированных данных. Предприятия активно используют ИИ для решения проблем нехватки рабочей силы и старения населения, особенно в здравоохранении и логистике. Спрос на мультимодальные и языковые наборы данных растёт по мере расширения применения ИИ в потребительской электронике и государственных услугах.
Обзор рынка наборов данных для обучения искусственного интеллекта в Китае
В 2024 году китайский рынок наборов данных для обучения с использованием ИИ обеспечил наибольшую долю выручки в Азиатско-Тихоокеанском регионе благодаря стратегии развития страны, ориентированной на ИИ, масштабной цифровизации и доминированию на рынке умных устройств. Широкое внедрение систем распознавания лиц, видеонаблюдения и электронной коммерции с использованием ИИ привело к огромному спросу на маркированные наборы данных. Поддерживаемые государством программы и рост числа отечественных компаний в сфере ИИ создали надежную экосистему для генерации, аннотации и распространения данных. Успешные инициативы Китая в области умных городов и беспилотных автомобилей продолжают создавать огромные возможности для поставщиков наборов данных.
Доля рынка наборов данных для обучения ИИ
Лидерами отрасли наборов данных для обучения ИИ являются в основном хорошо зарекомендовавшие себя компании, среди которых:
- Масштаб ИИ (США)
- Аппен (Австралия)
- Лайонбридж (США)
- AWS (США)
- Сама (США)
- Clickworker (Великобритания)
- Cogito Tech (США)
- CloudFactory (Великобритания)
- TELUS International (Канада)
- Иннодата (США)
- iMerit (США)
- TransPerfect (США)
- Google (США)
- LXT (Канада)
- IBM (США)
- Microsoft (США)
- NVIDIA (США)
Последние разработки на мировом рынке наборов данных для обучения ИИ
- В сентябре 2024 года компания Innodata запустила свой рынок данных для ИИ, что стало важным шагом на пути к решению проблем масштабируемости и доступности данных при обучении моделей ИИ/МО. Платформа предлагает тщательно отобранные синтетические наборы данных, доступные по запросу, которые помогают командам специалистов по анализу данных преодолевать ограничения, связанные с объемом, разнообразием и конфиденциальностью данных. Ожидается, что, упрощая доступ к готовым наборам данных, этот рынок ускорит разработку моделей ИИ и удовлетворит растущий спрос на синтетические и предметно-ориентированные данные для обучения в различных отраслях.
- В сентябре 2024 года компания SCALE AI объявила об инвестициях в размере 21 миллиона долларов США в девять проектов в сфере здравоохранения, основанных на ИИ, по всей Канаде в рамках Общеканадской стратегии развития искусственного интеллекта. Эта инициатива призвана существенно повлиять на рынок наборов данных для обучения ИИ в сфере здравоохранения, способствуя сотрудничеству между больницами и разработчиками ИИ. Она направлена на улучшение качества обслуживания пациентов, сокращение времени ожидания и оптимизацию работы системы здравоохранения, тем самым повышая спрос на высококачественные наборы данных, полученные из этичных источников и адаптированные для клинических, административных и диагностических приложений.
- В августе 2024 года компания Lionbridge Technologies, Inc. представила Aurora AI Studio — специализированную платформу, призванную помочь предприятиям в обучении моделей ИИ с использованием высококачественных наборов данных. Этот запуск отвечает растущей потребности в специализированных и качественно аннотированных данных для поддержки сложных сценариев использования ИИ. Используя глобальный опыт Lionbridge в курировании и аннотировании данных, платформа укрепляет коммерческую экосистему ИИ и готова влиять на спрос на специализированные, многоязычные и отраслевые наборы данных в таких секторах, как финансы, розничная торговля и телекоммуникации.
- В августе 2024 года компания Accenture в партнёрстве с Google Cloud ускорила внедрение решений для генеративного ИИ через свой Центр передового опыта в области генеративного ИИ. Переход 45% проектов в промышленную эксплуатацию свидетельствует о растущей масштабной операционализации ИИ. Это сотрудничество подчёркивает острую потребность в безопасных, разнообразных и готовых к использованию обучающих наборах данных, поддерживающих передовые модели ИИ на предприятиях. Инициатива также включает в себя кибербезопасность, усиливая роль ответственного обращения с данными и наборов данных, ориентированных на конфиденциальность, при внедрении ИИ на предприятиях.
- В июле 2024 года компания Microsoft Research представила AgentInstruct — многоагентную платформу для автоматизации генерации высококачественных синтетических данных. Продемонстрированная на примере модели Orca-3 в различных тестах, эта платформа минимизирует вмешательство человека в маркировку данных, тем самым снижая затраты и ускоряя создание наборов данных. Ожидается, что AgentInstruct изменит рынок наборов данных для обучения ИИ, продвигая использование синтетических данных для обучения крупномасштабных моделей, особенно в генеративном ИИ и базовых моделях.
SKU-
Получите онлайн-доступ к отчету на первой в мире облачной платформе рыночной аналитики
- Интерактивная панель анализа данных
- Панель анализа компании для возможностей с высоким потенциалом роста
- Доступ аналитика-исследователя для настройки и запросов
- Анализ конкурентов с помощью интерактивной панели
- Последние новости, обновления и анализ тенденций
- Используйте возможности сравнительного анализа для комплексного отслеживания конкурентов
Методология исследования
Сбор данных и анализ базового года выполняются с использованием модулей сбора данных с большими размерами выборки. Этап включает получение рыночной информации или связанных данных из различных источников и стратегий. Он включает изучение и планирование всех данных, полученных из прошлого заранее. Он также охватывает изучение несоответствий информации, наблюдаемых в различных источниках информации. Рыночные данные анализируются и оцениваются с использованием статистических и последовательных моделей рынка. Кроме того, анализ доли рынка и анализ ключевых тенденций являются основными факторами успеха в отчете о рынке. Чтобы узнать больше, пожалуйста, запросите звонок аналитика или оставьте свой запрос.
Ключевой методологией исследования, используемой исследовательской группой DBMR, является триангуляция данных, которая включает в себя интеллектуальный анализ данных, анализ влияния переменных данных на рынок и первичную (отраслевую экспертную) проверку. Модели данных включают сетку позиционирования поставщиков, анализ временной линии рынка, обзор рынка и руководство, сетку позиционирования компании, патентный анализ, анализ цен, анализ доли рынка компании, стандарты измерения, глобальный и региональный анализ и анализ доли поставщика. Чтобы узнать больше о методологии исследования, отправьте запрос, чтобы поговорить с нашими отраслевыми экспертами.
Доступна настройка
Data Bridge Market Research является лидером в области передовых формативных исследований. Мы гордимся тем, что предоставляем нашим существующим и новым клиентам данные и анализ, которые соответствуют и подходят их целям. Отчет можно настроить, включив в него анализ ценовых тенденций целевых брендов, понимание рынка для дополнительных стран (запросите список стран), данные о результатах клинических испытаний, обзор литературы, обновленный анализ рынка и продуктовой базы. Анализ рынка целевых конкурентов можно проанализировать от анализа на основе технологий до стратегий портфеля рынка. Мы можем добавить столько конкурентов, о которых вам нужны данные в нужном вам формате и стиле данных. Наша команда аналитиков также может предоставить вам данные в сырых файлах Excel, сводных таблицах (книга фактов) или помочь вам в создании презентаций из наборов данных, доступных в отчете.