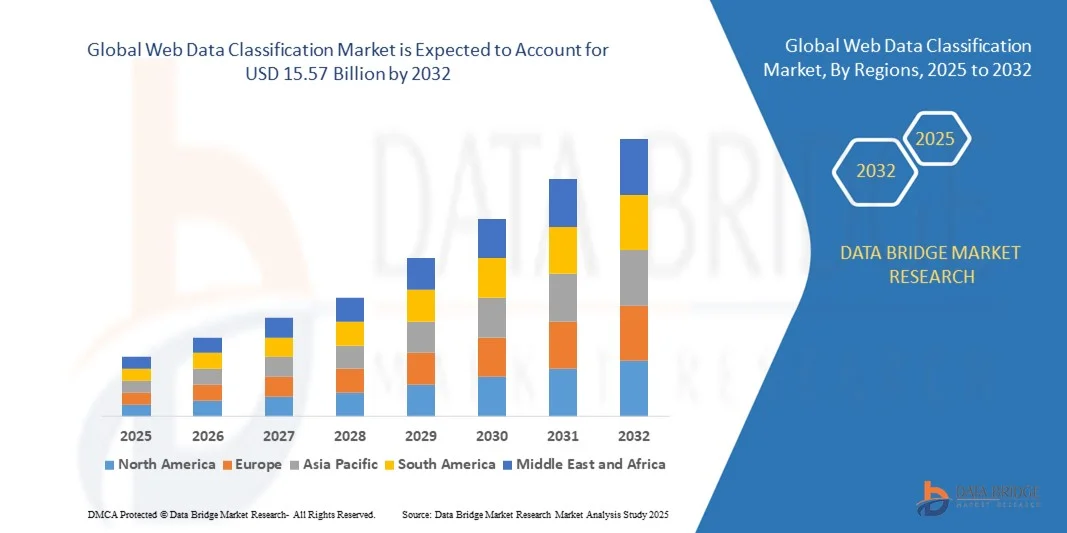
Global Web Data Classification Market
Размер рынка в млрд долларов США
CAGR :
% 
 USD
2.58 Billion
USD
15.57 Billion
2024
2032
USD
2.58 Billion
USD
15.57 Billion
2024
2032
| 2025 –2032 | |
| USD 2.58 Billion | |
| USD 15.57 Billion | |
| % | |
|
Сегментация глобального рынка классификации веб-данных по компонентам (решения и услуги), методологии (классификация на основе контента, контекстная классификация и классификация на основе пользователей), вертикали (банковское дело, финансовые услуги и страхование (BFSI), здравоохранение и науки о жизни, государственное управление и оборона, образование, телекоммуникации, СМИ и развлечения и другие) — тенденции отрасли и прогноз до 2032 года
Размер рынка веб-классификации данных
- Объем мирового рынка классификации веб-данных в 2024 году оценивался в 2,58 млрд долларов США , а к 2032 году , как ожидается, он достигнет 15,57 млрд долларов США при среднегодовом темпе роста 25,20% в прогнозируемый период.
- Рост рынка во многом обусловлен растущим внедрением искусственного интеллекта, машинного обучения и облачных решений, которые позволяют организациям эффективно классифицировать и управлять большими объемами структурированных и неструктурированных данных в различных отраслях.
- Более того, растущий спрос на безопасные, точные и автоматизированные решения для классификации данных побуждает предприятия внедрять передовые платформы, обеспечивающие соблюдение нормативных требований, конфиденциальность данных и расширенные возможности принятия решений. Эти факторы ускоряют внедрение решений для классификации веб-данных, значительно стимулируя рост рынка.
Анализ рынка классификации веб-данных
- Классификация веб-данных включает в себя процесс категоризации данных на основе контента, контекста или поведения пользователя для улучшения управления данными, их безопасности и доступности. Решения используют искусственный интеллект, семантический анализ и машинное обучение для оптимизации управления данными, сокращения ручного труда и повышения эффективности работы в различных секторах.
- Растущий спрос на классификацию веб-данных обусловлен, прежде всего, резким ростом объемов генерации цифровых данных, строгими правилами конфиденциальности данных и растущей потребностью организаций в получении практической информации из неструктурированной информации, тем самым способствуя принятию обоснованных бизнес-решений и повышению эксплуатационной устойчивости.
- Северная Америка доминировала на рынке классификации веб-данных с долей 33,3% в 2024 году благодаря растущему внедрению облачных вычислений, передовой аналитики и строгим правилам конфиденциальности данных, таким как CCPA.
- Ожидается, что Азиатско-Тихоокеанский регион станет самым быстрорастущим регионом на рынке классификации веб-данных в течение прогнозируемого периода благодаря росту цифровизации, расширению ИТ- и телекоммуникационной инфраструктуры, а также повышению осведомленности о защите данных в таких странах, как Китай, Япония и Индия.
- Сегмент решений доминировал на рынке с долей рынка 61,8% в 2024 году благодаря растущему внедрению передовых инструментов классификации на основе искусственного интеллекта и машинного обучения, которые помогают организациям эффективно организовывать и управлять большими объемами неструктурированных и структурированных данных. Решения предлагают автоматизированные, масштабируемые и точные возможности классификации, позволяя компаниям улучшить управление данными, соответствие требованиям и аналитику. Предприятия из разных отраслей отдают приоритет решениям, которые легко интегрируются с существующими ИТ-инфраструктурами и облачными средами, тем самым сокращая объем ручного труда и эксплуатационные расходы. Растущий спрос на аналитику данных в режиме реального времени и улучшенное принятие решений также способствует внедрению комплексных решений.
Область отчета и классификация веб-данных. Сегментация рынка
|
Атрибуты |
Ключевые аспекты рынка классификации веб-данных |
|
Охваченные сегменты |
|
|
Охваченные страны |
Северная Америка
Европа
Азиатско-Тихоокеанский регион
Ближний Восток и Африка
Южная Америка
|
|
Ключевые игроки рынка |
|
|
Рыночные возможности |
|
|
Информационные наборы данных с добавленной стоимостью |
Помимо таких рыночных данных, как рыночная стоимость, темпы роста, сегменты рынка, географический охват, участники рынка и рыночный сценарий, отчет о рынке, подготовленный командой Data Bridge Market Research, включает в себя углубленный экспертный анализ, анализ импорта/экспорта, анализ цен, анализ потребления продукции и анализ пестицидов. |
Тенденции рынка классификации веб-данных
Растущее использование ИИ для автоматизированной классификации данных
- Рынок классификации веб-данных стремительно растёт благодаря всё более широкому внедрению технологий искусственного интеллекта (ИИ) для автоматизации процессов категоризации и маркировки данных. Организации, работающие с большими объёмами онлайн- и корпоративных веб-данных, используют алгоритмы на базе ИИ для повышения точности, снижения ручной нагрузки и ускорения принятия решений.
- Например, IBM и Microsoft Azure интегрировали в свои облачные платформы механизмы классификации на основе машинного обучения, что позволяет автоматически маркировать конфиденциальную информацию, данные клиентов и конфиденциальный контент в соответствии с правилами конфиденциальности. Аналогичным образом, AWS Macie использует ИИ для идентификации и классификации персональных данных в облачных хранилищах, обеспечивая улучшенную прозрачность и контроль соответствия требованиям.
- Автоматизированные системы классификации на основе искусственного интеллекта способны обрабатывать большие наборы данных в режиме реального времени, эффективно различая структурированные, полуструктурированные и неструктурированные данные. Эти решения также адаптируются к меняющимся моделям данных, обеспечивая постоянное повышение точности посредством обучения моделей и обучения с подкреплением.
- Кроме того, классификация на основе ИИ повышает операционную эффективность в таких отраслях, как финансы, здравоохранение и розничная торговля, обеспечивая быструю идентификацию критически важных данных для аналитики, аудита соответствия и протоколов безопасности. Компании получают выгоду от снижения человеческого фактора, оптимизации рабочих процессов и улучшения управления данными.
- Интеграция обработки естественного языка (NLP) и моделей глубокого обучения в инструменты веб-классификации улучшает понимание контекста, обеспечивая точную категоризацию сложных наборов данных, таких как отзывы клиентов, юридические документы и мультимедийный контент. Ожидается, что эта тенденция будет усиливаться по мере того, как предприятия расширяют инициативы цифровой трансформации и нуждаются в масштабируемых интеллектуальных решениях для управления данными.
- По мере развития возможностей искусственного интеллекта автоматизированная классификация данных станет краеугольным камнем управления информацией, обеспечивая более быструю и безопасную обработку веб-данных в глобальных отраслях. Эта тенденция подчёркивает растущую зависимость от интеллектуальной автоматизации для управления крупномасштабными цифровыми активами в средах, ориентированных на регулирование и аналитику.
Динамика рынка классификации веб-данных
Водитель
Растущие потребности в соблюдении нормативных требований и обеспечении безопасности данных
- Ужесточение глобальных правил конфиденциальности и безопасности данных является основным драйвером рынка классификации веб-данных. Организации должны обеспечить соответствие таким стандартам, как GDPR, CCPA, HIPAA и PCI DSS, которые требуют точной идентификации, маркировки и защиты конфиденциальной информации, хранящейся в Интернете и во внутренних системах.
- Например, Forcepoint и Symantec предлагают решения для классификации, которые помогают компаниям обнаруживать и маркировать конфиденциальные бизнес-данные, персональные данные и платежные реквизиты для соблюдения нормативных требований. Эти инструменты обеспечивают автоматическое применение политик для безопасной обработки данных, одновременно снижая риск нарушений и штрафных санкций со стороны регулирующих органов.
- Растущая распространённость киберугроз и атак программ-вымогателей обострила необходимость точной классификации веб-данных для реализации эффективных мер контроля доступа и шифрования. Выявляя конфиденциальную и ценную информацию на ранних этапах жизненного цикла данных, предприятия могут укрепить систему безопасности и улучшить реагирование на инциденты.
- Кроме того, аудиты соответствия всё чаще требуют подтверждения мер по управлению данными. Системы классификации веб-данных обеспечивают документальное подтверждение прослеживаемости и отчётность, готовую к аудиту, что упрощает для организаций демонстрацию соблюдения правовых и отраслевых стандартов.
- Поскольку организации сталкиваются с растущими объемами данных и ужесточением контроля за цифровыми практиками, интеграция инструментов классификации в корпоративные рабочие процессы становится важнейшим шагом на пути к обеспечению целостности бизнеса и выполнению меняющихся требований по соблюдению нормативных требований во всем мире.
Сдержанность/Вызов
Управление быстрым ростом неструктурированных данных
- Одной из наиболее серьёзных проблем на рынке классификации веб-данных является управление экспоненциальным ростом объёма неструктурированных данных, таких как электронные письма, мультимедийные файлы, контент социальных сетей и сообщения клиентов. Неструктурированные наборы данных часто не имеют единого форматирования, что затрудняет их анализ и точную классификацию.
- Например, такие компании, как OpenText и Informatica, постоянно сталкиваются с трудностями при классификации больших неструктурированных архивов, обеспечивая при этом точность данных на разных языках, в разных форматах и с постоянно меняющейся структурой контента. Динамичность текстовых, видео- и графических данных требует использования передовых аналитических моделей и их постоянного совершенствования для эффективной классификации.
- Огромный объём неструктурированных веб-данных также может создавать нагрузку на вычислительные ресурсы, что приводит к увеличению затрат на обработку и времени классификации. Для эффективного управления такими рабочими нагрузками предприятиям часто требуются значительные инвестиции в инфраструктуру ИИ, облачное хранилище и масштабируемые вычислительные мощности.
- Кроме того, неточная классификация неструктурированных данных может привести к ненадлежащему управлению конфиденциальной информацией, создавая риски нарушения требований и подрывая протоколы безопасности. Обеспечение точности маркировки требует высококачественных обучающих наборов данных, разработка которых может быть дорогостоящей и трудоёмкой.
- Несмотря на то, что достижения в области искусственного интеллекта, обработки естественного языка и глубокого обучения расширяют возможности, непредсказуемость и огромное разнообразие неструктурированных данных по-прежнему представляют собой серьёзные препятствия. Преодоление этих проблем потребует инноваций в адаптивных моделях классификации, гибридных системах управления данными и инструментах обработки в режиме реального времени для поддержания точности при обработке быстро растущих объёмов данных.
Сфера применения рынка классификации веб-данных
Рынок сегментирован по принципу компонентов, методологии и вертикали.
- По компонентам
По компонентному составу рынок классификации веб-данных сегментируется на решения и услуги. Сегмент решений занял наибольшую долю рынка – 61,8% – в 2024 году благодаря растущему внедрению передовых инструментов классификации на основе искусственного интеллекта и машинного обучения, которые помогают организациям эффективно организовывать и управлять большими объемами неструктурированных и структурированных данных. Решения предлагают автоматизированные, масштабируемые и точные возможности классификации, позволяя компаниям улучшить управление данными, соответствие требованиям и аналитику. Предприятия из разных отраслей отдают приоритет решениям, которые легко интегрируются с существующими ИТ-инфраструктурами и облачными средами, тем самым сокращая объем ручного труда и эксплуатационные расходы. Растущий спрос на аналитику данных в режиме реального времени и улучшенный процесс принятия решений также способствует внедрению комплексных решений.
Ожидается, что сегмент услуг будет демонстрировать самые высокие темпы роста в период с 2025 по 2032 год, что обусловлено растущей зависимостью от профессионального консалтинга, внедрения и управления проектами классификации данных. Сервисы предоставляют индивидуальные решения, адаптированные к конкретной среде данных организации, обеспечивая более высокую точность и соответствие отраслевым стандартам. Компании, которым не хватает собственных специалистов, предпочитают услуги по развертыванию, мониторингу и постоянной оптимизации систем классификации. Более того, управляемые услуги и предложения на основе подписки делают внедрение расширенных возможностей классификации экономически выгодным для малых и средних предприятий.
- По методологии
По методологии рынок классификации веб-данных сегментируется на классификацию на основе контента, контекстную классификацию и пользовательскую классификацию. Сегмент классификации на основе контента занял наибольшую долю рынка в 2024 году благодаря своей способности анализировать внутренние свойства данных, включая ключевые слова, метаданные и структуру документов, для точной категоризации и тегирования контента. Эта методология широко используется компаниями, которым требуются автоматизированные масштабируемые решения для классификации, минимизирующие вмешательство человека и обеспечивающие соответствие нормативным требованиям. Эффективность этой методологии при работе с большими наборами данных в сфере банковских и финансовых услуг, здравоохранения и государственного сектора обеспечивает её доминирующее положение на рынке.
Ожидается, что сегмент контекстной классификации будет демонстрировать самые высокие среднегодовые темпы роста в период с 2025 по 2032 год, что обусловлено растущим спросом на интеллектуальные системы классификации, учитывающие контекст, взаимосвязи и семантическое значение данных. Контекстно-ориентированные подходы позволяют организациям получать более глубокий анализ, улучшать персонализацию и эффективнее выявлять аномалии. Предприятия, обрабатывающие сложные наборы данных, такие как финансовые транзакции или истории болезни пациентов, все чаще внедряют контекстно-ориентированные методологии для повышения точности, снижения количества ошибок и оптимизации рабочих процессов.
- По вертикали
По вертикали рынок классификации веб-данных сегментируется на следующие сферы: BFSI, здравоохранение и науки о жизни, государственное управление и оборона, образование, телекоммуникации, СМИ и индустрия развлечений и другие. Вертикаль BFSI заняла наибольшую долю рынка в 2024 году, что обусловлено острой потребностью в безопасной, эффективной и соответствующей требованиям обработке конфиденциальных финансовых данных. Банки, страховые и инвестиционные компании все чаще используют автоматизированные системы классификации для оптимизации оценки рисков, соблюдения нормативных требований, выявления мошенничества и аналитики данных клиентов. Большой объем транзакционных и генерируемых клиентами данных дополнительно усиливает спрос на передовые решения в этом секторе.
Ожидается, что сектор здравоохранения и наук о жизни будет демонстрировать самые высокие темпы роста в период с 2025 по 2032 год, чему будет способствовать растущая оцифровка медицинских карт, исследовательских данных и информации клинических испытаний. Медицинские организации внедряют веб-классификацию данных для улучшения управления данными пациентов, ускорения исследований и обеспечения соответствия таким нормативным требованиям, как HIPAA и GDPR. Передовые методологии классификации помогают упорядочивать неструктурированные медицинские карты, облегчая анализ данных в режиме реального времени, предиктивную аналитику и персонализированный уход за пациентами. Растущее внедрение технологий искусственного интеллекта и машинного обучения в больницах, лабораториях и фармацевтических компаниях дополнительно ускоряет рост в этом секторе.
Региональный анализ рынка классификации веб-данных
- Северная Америка доминировала на рынке классификации веб-данных с наибольшей долей выручки в 33,3% в 2024 году, что обусловлено растущим внедрением облачных вычислений, передовой аналитики и строгими правилами конфиденциальности данных, такими как CCPA.
- Предприятия региона уделяют первостепенное внимание управлению данными и соблюдению нормативных требований, чтобы справиться с растущей обеспокоенностью по поводу киберугроз и неправомерного использования информации.
- Сильное присутствие крупных поставщиков технологий, раннее внедрение инструментов классификации данных на основе ИИ и крупные инвестиции в инфраструктуру безопасности данных еще больше усиливают региональное доминирование.
Обзор рынка классификации веб-данных в США
Рынок классификации веб-данных в США в 2024 году занял наибольшую долю выручки в Северной Америке благодаря быстрому внедрению инициатив цифровой трансформации и усилению внимания к соблюдению нормативных требований. Резкий рост генерации неструктурированных данных в сочетании с расширением использования облачных технологий на предприятиях является драйвером роста рынка. Более того, присутствие крупных технологических компаний и растущее внедрение в сфере бизнес-финансирования, здравоохранения и государственного сектора продолжают стимулировать расширение рынка.
Обзор европейского рынка классификации веб-данных
Ожидается, что европейский рынок классификации веб-данных будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, что обусловлено, главным образом, строгими правилами защиты данных, такими как GDPR, и растущим вниманием к защите корпоративных данных. Рост цифровизации в отраслях и растущее внедрение автоматизированных решений для управления данными способствуют их внедрению. Европейские организации делают акцент на системах классификации на основе искусственного интеллекта для оптимизации соблюдения нормативных требований, повышения прозрачности и снижения рисков утечки данных.
Обзор рынка классификации веб-данных в Великобритании
Ожидается, что рынок классификации веб-данных в Великобритании будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, что обусловлено ужесточением законов о конфиденциальности данных и расширением использования цифровых технологий в финансовом, государственном секторах и здравоохранении. Рост инвестиций в инфраструктуру данных в регионе в сочетании с растущим спросом на автоматизированные инструменты обработки данных и обеспечения соответствия требованиям стимулирует рост рынка.
Обзор рынка классификации веб-данных в Германии
Ожидается, что рынок классификации веб-данных в Германии будет расти значительными среднегодовыми темпами в течение прогнозируемого периода, чему будет способствовать особое внимание, уделяемое страной кибербезопасности, соблюдению нормативных требований и цифровизации промышленности. Предприятия производственного и государственного секторов внедряют платформы классификации на основе искусственного интеллекта для эффективного управления большими объемами данных. Особое внимание Германии к суверенитету данных и инновационной ИТ-политике продолжает способствовать устойчивому расширению рынка.
Обзор рынка классификации веб-данных в Азиатско-Тихоокеанском регионе
Рынок классификации веб-данных в Азиатско-Тихоокеанском регионе, как ожидается, будет расти самыми быстрыми темпами в год в период с 2025 по 2032 год, что обусловлено ростом цифровизации, развитием ИТ- и телекоммуникационной инфраструктуры, а также растущей осведомлённостью о защите данных в таких странах, как Китай, Япония и Индия. Стремительный рост электронной коммерции и облачных сервисов, а также государственные инициативы по продвижению цифрового управления, ускоряют внедрение этих технологий. Ожидается, что большой объём данных в регионе и развивающиеся возможности искусственного интеллекта будут способствовать поддержанию устойчивой динамики роста.
Обзор рынка классификации веб-данных в Китае
Рынок классификации веб-данных в Китае в 2024 году обеспечил наибольшую долю выручки в Азиатско-Тихоокеанском регионе благодаря строгим государственным требованиям к безопасности данных и быстрому внедрению этой технологии в электронной коммерции, финансах и государственном секторе. Акцент Китая на создании безопасных цифровых экосистем, поддерживаемый отечественными поставщиками ИИ и достижениями в области облачных технологий, продолжает стимулировать рост рынка.
Обзор рынка классификации веб-данных в Японии
Рынок классификации веб-данных в Японии набирает обороты благодаря технологическому прогрессу страны, высоким стандартам соответствия нормативным требованиям и растущему внедрению искусственного интеллекта и аналитики больших данных. Рост числа инициатив цифровой трансформации в здравоохранении, банковских и финансовых учреждениях (BFSI) и государственном секторе, а также спрос на безопасное и эффективное управление данными способствуют устойчивому росту рынка.
Доля рынка веб-классификации данных
Лидерами отрасли классификации веб-данных являются в основном хорошо зарекомендовавшие себя компании, в том числе:
- Корпорация IBM (США)
- Google (США)
- Microsoft (США)
- Amazon Web Services, Inc. (США)
- Broadcom (США)
- Open Text Corporation (Канада)
- БОЛДОН ДЖЕЙМС (Великобритания)
- Варонис (США)
- Innovative Routines International (IRI), Inc. (США)
- MinerEye (Израиль)
- PKWARE, Inc. (США)
- Informatica Corporation (США)
- Spirion, LLC (США)
- Clearswift GmbH (Германия)
- SECLORE (Индия)
- Титус (Канада)
- Корпорация Netwrix (США)
- GTB Technologies, Inc. (США)
- Forcepoint (США)
- ConnectWise, LLC (США)
- SoftWorks AI (США)
- Janusnet Pty Limited (Австралия)
Последние разработки на мировом рынке классификации веб-данных
- В октябре 2025 года компания Clarivate запустила свой классификатор на основе искусственного интеллекта (ИИ) Innography, предлагающий возможности классификации патентов с точностью до 97% с первого прохода. Это достижение отражает растущую потребность в системах классификации на основе искусственного интеллекта для автоматизации категоризации больших объемов данных и повышения точности принятия решений в компаниях. Сокращая объем ручного вмешательства и повышая эффективность бенчмаркинга, это нововведение усиливает интеграцию интеллектуальной классификации данных в стратегические бизнес-операции.
- В сентябре 2025 года компания Squirro, мировой лидер в области корпоративных решений для генеративного искусственного интеллекта и графов знаний, объявила о выпуске новейшего обновления своей платформы, представляющего классификатор Squirro. Это обновление улучшает управление корпоративными данными благодаря автоматизированной классификации, соответствующей организационной таксономии, расширенному обнаружению персональных данных (PII) и маскированию для соблюдения конфиденциальности. Эти обновления значительно повышают точность данных, их безопасность и контекстную аналитику, позволяя организациям получать более глубокий анализ неструктурированных данных.
- В июне 2025 года компания Zscaler представила новые функции классификации данных на базе искусственного интеллекта, предназначенные для идентификации и категоризации более 200 типов конфиденциальных данных с точностью, сравнимой с человеческой. Это достижение подчёркивает ускоряющуюся интеграцию искусственного интеллекта в системы безопасности данных, улучшая контекстный анализ и эффективность классификации в режиме реального времени. Расширение функций знаменует собой важный шаг на пути к обеспечению безопасной и интеллектуальной обработки больших объёмов конфиденциальной информации для предприятий.
- В июне 2025 года компания Progress выпустила расширенное обновление своей платформы Semaphore, включающее возможности семантического ИИ, автоматизирующие извлечение и классификацию структурированных и неструктурированных данных. Этот выпуск демонстрирует продолжающуюся конвергенцию управления знаниями и управления данными, предоставляя предприятиям возможность более эффективно управлять, интерпретировать и защищать данные. Интеграция с семантическим интеллектом способствует повышению уровня соответствия требованиям, прозрачности операционной деятельности и формированию аналитической информации.
- В августе 2024 года компания Varonis представила решение для обнаружения и классификации данных на базе искусственного интеллекта (ИИ), расширяющее возможности предприятий по обнаружению, мониторингу и классификации конфиденциальной информации в различных средах хранения. Это решение отражает растущий спрос на интеллектуальную автоматизацию для выявления высокорисковых данных и применения протоколов защиты. Повышая прозрачность и контроль над корпоративными данными, решение способствует повышению уровня соответствия нормативным требованиям и безопасности в различных отраслях.
SKU-
Получите онлайн-доступ к отчету на первой в мире облачной платформе рыночной аналитики
- Интерактивная панель анализа данных
- Панель анализа компании для возможностей с высоким потенциалом роста
- Доступ аналитика-исследователя для настройки и запросов
- Анализ конкурентов с помощью интерактивной панели
- Последние новости, обновления и анализ тенденций
- Используйте возможности сравнительного анализа для комплексного отслеживания конкурентов
Методология исследования
Сбор данных и анализ базового года выполняются с использованием модулей сбора данных с большими размерами выборки. Этап включает получение рыночной информации или связанных данных из различных источников и стратегий. Он включает изучение и планирование всех данных, полученных из прошлого заранее. Он также охватывает изучение несоответствий информации, наблюдаемых в различных источниках информации. Рыночные данные анализируются и оцениваются с использованием статистических и последовательных моделей рынка. Кроме того, анализ доли рынка и анализ ключевых тенденций являются основными факторами успеха в отчете о рынке. Чтобы узнать больше, пожалуйста, запросите звонок аналитика или оставьте свой запрос.
Ключевой методологией исследования, используемой исследовательской группой DBMR, является триангуляция данных, которая включает в себя интеллектуальный анализ данных, анализ влияния переменных данных на рынок и первичную (отраслевую экспертную) проверку. Модели данных включают сетку позиционирования поставщиков, анализ временной линии рынка, обзор рынка и руководство, сетку позиционирования компании, патентный анализ, анализ цен, анализ доли рынка компании, стандарты измерения, глобальный и региональный анализ и анализ доли поставщика. Чтобы узнать больше о методологии исследования, отправьте запрос, чтобы поговорить с нашими отраслевыми экспертами.
Доступна настройка
Data Bridge Market Research является лидером в области передовых формативных исследований. Мы гордимся тем, что предоставляем нашим существующим и новым клиентам данные и анализ, которые соответствуют и подходят их целям. Отчет можно настроить, включив в него анализ ценовых тенденций целевых брендов, понимание рынка для дополнительных стран (запросите список стран), данные о результатах клинических испытаний, обзор литературы, обновленный анализ рынка и продуктовой базы. Анализ рынка целевых конкурентов можно проанализировать от анализа на основе технологий до стратегий портфеля рынка. Мы можем добавить столько конкурентов, о которых вам нужны данные в нужном вам формате и стиле данных. Наша команда аналитиков также может предоставить вам данные в сырых файлах Excel, сводных таблицах (книга фактов) или помочь вам в создании презентаций из наборов данных, доступных в отчете.