Global Data Wrangling Market
시장 규모 (USD 10억)
연평균 성장률 :
% 
 USD
3.32 Billion
USD
7.48 Billion
2025
2033
USD
3.32 Billion
USD
7.48 Billion
2025
2033
| 2026 –2033 | |
| USD 3.32 Billion | |
| USD 7.48 Billion | |
| % | |
|
글로벌 데이터 랭글링 시장, 사업 기능(재무, 마케팅 및 영업, 운영, 인사 및 법률), 구성 요소(도구 및 서비스), 배포 모델(온프레미스 및 클라우드), 조직 규모(대기업 및 중소기업), 산업 분야(은행, 금융 서비스 및 보험, 정부 및 공공 부문, 의료 및 생명 과학, 소매 및 전자상거래, 여행 및 호텔, 자동차 및 운송, 에너지 및 유틸리티, 통신 및 IT, 제조 및 기타)별 - 2032년까지의 산업 동향 및 전망
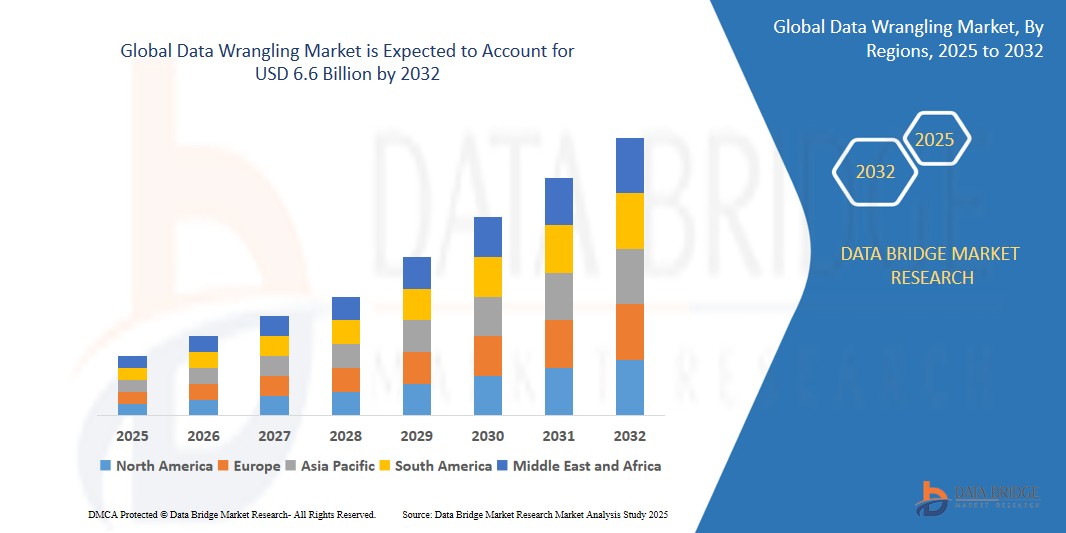
데이터 정리 시장 규모
- 데이터 랭글링 시장은 2024년에 30억 달러 규모로 평가되었으며 2032년에는 66억 달러 에 이를 것으로 예상됩니다 .
- 2025년부터 2032년까지의 예측 기간 동안 시장은 주로 신흥 분야의 높은 연구 최적화와 성장에 힘입어 연평균 성장률 10.7% 로 성장할 것으로 예상됩니다.
- 이러한 성장은 AI 기반 자동화 도입 증가에 따른 것으로, 이를 통해 데이터 준비 효율성이 높아지고 수동 작업이 감소했습니다.
데이터 정리 시장 분석
- 금융, 의료, 소매, 통신 등 산업 전반에서 데이터 처리를 간소화하고, 의사 결정을 강화하고, 운영 효율성을 높이기 위해 데이터 정리가 점점 더 많이 도입되고 있습니다.
- AI, 머신 러닝 및 자동화의 발전으로 데이터 정리가 혁신되어 분석, 비즈니스 인텔리전스 및 예측 모델링을 위한 더 빠르고 정확한 데이터 준비가 가능해졌습니다.
- 조직은 증가하는 데이터 복잡성을 처리하고 클라우드 및 빅 데이터 환경에서 확장성을 개선하기 위해 수동 데이터 정리에서 자동화된 데이터 정리 솔루션으로 전환하고 있습니다.
- 실시간 데이터 정리 도구는 구조화된 데이터 소스와 구조화되지 않은 데이터 소스를 통합하여 실행 가능한 통찰력을 제공하고, 기업에 더 나은 예측, 개인화된 서비스, 데이터 기반 전략에 대한 더 높은 ROI를 제공합니다.
- 북미는 데이터 랭글링 서비스 도입이 증가하고 매일 수집되는 데이터로 인해 대규모 데이터 랭글링 수요가 증가함에 따라 예측 기간 동안 데이터 랭글링 시장을 지배할 것으로 예상됩니다.
보고 범위 및 데이터 정리 시장 세분화
|
속성 |
데이터 정리 시장 주요 시장 통찰력 |
|
다루는 세그먼트 |
|
|
포함 국가 |
북아메리카
유럽
아시아 태평양
중동 및 아프리카
남아메리카
남미의 나머지 지역 |
|
주요 시장 참여자 |
|
|
시장 기회 |
|
|
부가가치 데이터 정보 세트 |
Data Bridge Market Research 팀이 큐레이팅한 시장 보고서에는 시장 가치, 성장률, 시장 부문, 지리적 범위, 시장 참여자, 시장 시나리오와 같은 시장 통찰력 외에도 심층적인 전문가 분석, 수입/수출 분석, 가격 분석, 생산 소비 분석, PORTER 분석, PESTLE 분석이 포함되어 있습니다. |
데이터 정리 시장 동향
"클라우드 기반 데이터 정리 솔루션 도입 증가"
- 클라우드 기반 데이터 랭글링 솔루션은 방대한 데이터 세트를 처리할 수 있도록 동적으로 확장되어 분산된 데이터 환경에서 고속 처리, 효율적인 리소스 할당, 중단 없는 워크플로를 보장합니다. 클라우드 솔루션은 실시간 협업, 자동 업데이트, AI 기반 분석 도구와의 원활한 통합을 지원하여 더욱 스마트한 의사 결정을 지원하므로 기업은 IT 인프라 비용을 절감하는 동시에 접근성을 향상할 수 있습니다.
- 강력한 암호화, 액세스 제어 및 규정 준수 프레임워크는 데이터 무결성과 보호를 보장하여 조직이 클라우드 생태계에서 구조화된 데이터와 구조화되지 않은 데이터를 안전하게 관리하는 동시에 업계 규정을 준수할 수 있도록 지원합니다.
- 클라우드 기반 데이터 정리를 통해 즉각적인 데이터 변환이 가능하고, 빅데이터, IoT, AI 기반 분석과 원활하게 통합되어 더 빠른 통찰력을 제공하고 비즈니스 인텔리전스 역량을 개선할 수 있습니다.
예를 들어,
- 포브스 미디어 LLC가 게시한 블로그에 따르면, 2025년 4월, 다음 주 라스베이거스에서 개최될 예정인 구글 클라우드 넥스트 2025(Google Cloud Next 2025)는 AI 기반 데이터 랭글링, 클라우드 컴퓨팅, 그리고 분석 분야의 발전을 집중 조명할 예정입니다. 제미니 기반 데이터베이스와 AI 기반 데이터 관리 도구와 같은 혁신을 통해 산업 전반에 걸쳐 클라우드, AI, 그리고 데이터 솔루션을 통합하려는 구글의 전략을 선보일 예정입니다. 또한, 이 행사는 개발자 역량 강화 및 AI 인재 확대에도 중점을 두고, 클라우드 기술 분야에서 구글의 경쟁력을 강화할 것입니다.
- 또한, 클라우드 플랫폼은 머신 러닝과 AI를 활용하여 데이터 정리, 중복 제거 및 변환을 자동화하여 수동 오류를 줄이고, 정확성을 높이고, 더 나은 의사 결정을 위해 데이터 워크플로를 최적화합니다.
데이터 정리 시장 동향
운전사
“데이터 처리 분야에서 AI 및 자동화 도입 증가”
- 데이터 처리에 AI와 자동화가 점점 더 많이 도입됨에 따라 효율성과 정확성이 향상되어 데이터 랭글링 시장이 크게 성장하고 있습니다. 기존의 데이터 랭글링 방식은 시간이 많이 소요되고 인적 오류가 발생하기 쉬운 반면, AI 기반 자동화는 획기적인 변화를 가져올 것입니다. 머신러닝 알고리즘을 활용하면 기업은 데이터 정리, 변환 및 통합을 자동화하여 수작업을 줄이는 동시에 데이터 품질을 향상시킬 수 있습니다.
- AI 기반 자동화는 실시간 데이터 랭글링을 지원하여 기업이 즉시 인사이트를 도출하고 데이터 기반 의사 결정을 더욱 신속하게 내릴 수 있도록 합니다. 금융, 의료, 소매업 등의 산업은 사기 탐지, 예측 모델링, 개인화된 고객 경험을 위해 실시간 분석에 점점 더 의존하고 있습니다. 자동화된 데이터 랭글링 도구는 AI 기반 분석 플랫폼과 통합하는 동시에 데이터 세트를 지속적으로 개선하고 일관성과 안정성을 보장하는 데 도움이 됩니다.
예를 들어,
2025년 4월, 블룸버그의 CTO인 숀 에드워즈는 AI가 애널리스트 업무량의 80%를 간소화하여 생산성을 크게 향상시킬 수 있다고 밝혔습니다. 파이낸셜 뉴스와의 인터뷰에서 그는 생성적 AI가 특히 비정형 데이터 처리 시 리서치 효율성을 어떻게 향상시킬 수 있는지 강조했습니다. 이 시장 데이터 대기업은 주니어 뱅킹의 역할에 혁신을 가져올 AI 기반 도구를 개발하고 있으며, 특정 분야의 생산성을 10배까지 향상시켜 금융 리서치 및 분석을 혁신하고 있습니다.
기회
“데이터 거버넌스 및 규정 준수 솔루션에 대한 수요 증가”
- 데이터 거버넌스 및 규정 준수에 대한 요구가 증가함에 따라 데이터 랭글링 시장 수요가 증가하고 있습니다. GDPR 및 CCPA와 같은 규제로 인해 기업은 데이터 정확성, 보안 및 추적성을 보장해야 합니다.
- 금융, 의료, 정부 등의 분야에서는 데이터 표준화, 감사 지원, 무단 접근 방지를 위해 고급 데이터 랭글링(Wrangling) 도구를 활용합니다. AI 기반 자동화는 데이터 계보 추적 및 변화하는 규정 준수를 향상시킵니다.
- 기업이 클라우드와 하이브리드 환경을 도입함에 따라 데이터 수집 도구에 내장된 거버넌스, 암호화 및 액세스 제어 기능은 규정 준수 위험을 관리하는 데 필수적입니다.
예를 들어,
- 2025년 2월, COMPLY는 AI 기반 컴플라이언스 자동화 및 데이터 거버넌스를 강조하는 2025 혁신 로드맵을 발표했습니다. 새로운 Employee360 대시보드는 최고 컴플라이언스 책임자(CCO)에게 직원 위험 및 규제 의무에 대한 실시간 감독 기능을 제공합니다. 규제 복잡성이 증가함에 따라 이는 데이터 거버넌스 및 컴플라이언스 솔루션에 대한 수요 증가를 부각하며, 데이터 랭글링 시장에서 금융 서비스 기업의 규제 데이터 관리를 간소화하고, 정확성을 향상시키며, 컴플라이언스 프로세스를 자동화할 수 있는 중요한 기회를 제공합니다.
- 데이터 거버넌스와 규정 준수에 대한 중요성이 커짐에 따라 데이터 랭글링(data wrangling)은 조직의 핵심 역량으로 자리 잡고 있습니다. 최신 데이터 랭글링 도구는 데이터 준비를 간소화할 뿐만 아니라 내장된 검증 및 보안 기능을 통해 규정 준수를 보장합니다.
제지/도전
“데이터 정리 및 자동화 분야의 숙련된 전문가 부족”
- 데이터 기반 의사 결정의 급속한 성장으로 데이터 랭글링(data wrangling) 분야의 숙련된 전문가에 대한 수요가 증가했습니다. 그러나 복잡한 데이터 변환, AI 기반 자동화, 그리고 규정 준수에 능숙한 전문가는 심각하게 부족합니다. 많은 조직이 대규모 비정형 데이터 세트를 효율적으로 관리, 정리 및 구조화할 수 있는 자격을 갖춘 인재를 찾는 데 어려움을 겪고 있습니다.
- 데이터 랭글링에는 데이터 엔지니어링, AI, 머신러닝을 포함한 여러 분야의 전문 지식이 필요합니다. 이러한 분야를 통합하는 과정은 복잡하기 때문에 적합한 기술을 갖춘 전문가를 찾는 것이 어렵습니다.
- GDPR 및 CCPA와 같은 진화하는 데이터 개인정보 보호 규정을 준수하는 것은 데이터 랭글링의 복잡성을 한층 더 가중시킵니다. 기업은 보안 기준을 유지하면서 데이터 거버넌스를 보장할 수 있는 전문가를 필요로 합니다. 데이터 랭글링 전문 지식을 갖춘 규정 준수 전문가 부족은 규제 위반 위험을 증가시켜 법적 및 재정적 손실을 초래합니다.
예를 들어,
- PRNewswire 보도에 따르면, 2024년 8월, 멀티버스(Multiverse) 보고서에 따르면 데이터 처리의 비효율성으로 인해 기업에서 직원 1인당 연간 26일의 데이터 기술 격차가 발생하는 것으로 나타났습니다. 미국과 영국의 18개 산업에 종사하는 직원 12,000명을 분석한 이 연구는 직원들이 주중 36%를 데이터 작업에 사용하며, 비효율성으로 인해 4.34시간이 손실되는 것으로 나타났습니다. 이러한 결과는 직원들의 데이터 리터러시, 자동화, 그리고 예측 모델링 역량 향상이 시급함을 보여줍니다.
- 데이터 랭글링 및 자동화 분야의 숙련된 전문가 부족은 복잡한 데이터를 효율적으로 관리하려는 조직에 어려움을 야기합니다. 이러한 격차는 수동 작업을 줄여주는 사용자 친화적인 AI 기반 도구의 필요성을 증대시킵니다.
데이터 정리 시장 범위
시장은 사업 기능, 구성 요소, 배포 모델, 조직 규모 및 산업 수직을 기준으로 5개의 주요 세그먼트로 구분됩니다.
|
분할 |
하위 세분화 |
|
사업 기능별 |
|
|
구성 요소별 |
|
|
배포 모델별 |
|
|
조직 규모별 |
|
|
산업별 수직별 |
|
데이터 정리 시장 국가 분석
“북미는 글로벌 데이터 랭글링 시장에서 지배적인 지역입니다.”
- 북미는 AI, 머신 러닝, 자동화 도구를 조기에 도입하여 기업이 데이터 처리와 분석을 간소화할 수 있게 되면서 글로벌 데이터 수집 시장을 선도하고 있습니다.
- 이 지역에는 IBM, 마이크로소프트, 구글, 아마존 등 글로벌 기술 선도 기업들이 자리 잡고 있으며, 이들은 데이터 관리 솔루션을 끊임없이 혁신하고 확장하고 있습니다. AI 기반 데이터 처리 스타트업에 대한 벤처 캐피털 자금 지원과 기업 투자 또한 시장 성장을 촉진하고 있습니다.
- 또한 기업과 AI 연구 기관 간의 협업을 통해 업계별 요구 사항에 맞는 보다 정교한 데이터 정리 도구를 개발할 수 있습니다.
“아시아 태평양 지역이 가장 높은 성장률을 기록할 것으로 예상됩니다.”
- 아시아 태평양 지역은 급속한 디지털 변혁을 겪고 있으며, 업계에서는 AI 기반 분석 및 자동화를 도입하고 있습니다. 클라우드 인프라 및 데이터 솔루션에 대한 투자가 급증하면서 효율적인 데이터 랭글링 도구에 대한 수요가 증가하고 있습니다.
- 전자상거래, 핀테크, 스마트 시티의 성장은 방대한 양의 비정형 데이터를 생성하고 있으며, 이로 인해 고급 랭글링(wrangling) 역량에 대한 필요성이 커지고 있습니다. 중국, 인도, 일본과 같은 국가들은 경쟁력 있는 인사이트를 확보하기 위해 실시간 데이터 처리를 우선시하고 있습니다.
- 중국의 PIPL과 인도의 DPDP법을 포함한 더욱 엄격해진 데이터 보호법으로 인해 기업은 규정 준수, 정확성, 간소화된 규제 보고를 보장하는 데이터 정리 도구를 도입해야 합니다.
데이터 정리 시장 점유율
시장 경쟁 구도는 경쟁사별 세부 정보를 제공합니다. 여기에는 회사 개요, 회사 재무 상태, 매출 창출, 시장 잠재력, 연구 개발 투자, 신규 시장 진출, 글로벌 입지, 생산 시설 및 설비, 생산 능력, 회사의 강점과 약점, 제품 출시, 제품 종류 및 범위, 응용 분야별 우위 등이 포함됩니다. 위에 제공된 데이터는 해당 회사의 시장 집중도와 관련된 데이터입니다.
시장에서 활동하는 주요 시장 리더는 다음과 같습니다.
- 트리팩타(미국)
- 데이터워치 시스템즈(미국)
- 다타이쿠(프랑스)
- IBM(미국)
- SAS Institute Inc.(미국)
- 오라클(미국)
- 탈렌드(프랑스)
- 알테릭스 주식회사(미국)
- TIBCO 소프트웨어 주식회사(미국)
- 팍사타 주식회사(미국)
- 인포매티카(미국)
- Hitachi Vantara Corporation(일본)
- 테라데이터(미국)
- 데이터미어(미국)
- 쿨라다타(이스라엘)
- 유비퀴티 주식회사(미국)
- Rapid Insight(미국)
- 인포직스 주식회사(미국)
- 잘로니(미국)
- Impetus Technologies Inc.(미국)
- Ideata Analytics(인도)
- Onedot AG(스위스)
- IRI(미국)
- 브릴리오(미국)
- TMM데이터(미국)
데이터 랭글링 시장의 최신 동향
2024년 10월, DataPelago는 GenAI 및 분석 워크로드를 위해 모든 하드웨어에서 모든 엔진을 가속화하는 범용 데이터 처리 엔진(UDP)을 출시했습니다. 4,700만 달러의 투자금을 지원받은 이 엔진은 증가하는 데이터 복잡성과 비정형 데이터 문제를 해결합니다. 이 엔진은 데이터 처리 효율성을 재정의하고 비용 및 확장성 한계를 극복합니다. CEO 라잔 고얄은 가속 컴퓨팅 시대에 다양한 형식의 방대하고 복잡한 데이터 세트를 처리하여 획기적인 인텔리전스를 구현할 수 있는 DataPelago의 역량을 강조합니다.
2025년 4월, 도이체텔레콤은 구글 클라우드와의 파트너십을 확대하여 '원 데이터 에코시스템'의 중추를 구축하고 데이터 시스템 효율화, 처리 속도 향상, 규제 준수를 보장합니다. 이러한 협력은 도이체텔레콤의 AI 중심 혁신을 지원하여 MyMagenta 앱의 Gemini 어시스턴트와 같은 AI 기반 솔루션을 통해 운영 및 고객 경험을 향상시킵니다. 또한, 구글 클라우드는 도이체텔레콤의 새로운 AI 플랫폼을 지원하여 더 나은 사용자 경험을 위한 혁신과 유연성을 촉진할 것입니다.
2025년 2월, 네덜란드 개인정보보호감독기구(AP)는 중국 AI 기업 DeepSeek의 데이터 수집 관행 및 개인정보 보호 정책에 대한 우려를 제기하며 조사를 시작했습니다. 이 조사는 이탈리아가 DeepSeek 앱을 금지한 데 이어 진행되었으며, 아일랜드와 프랑스 등 다른 EU 국가들은 DeepSeek의 데이터 처리 방식에 대한 정보를 요청하고 있습니다. EU의 엄격한 데이터 개인정보 보호 규정은 안전하고 규정을 준수하는 데이터 처리 관행의 중요성을 강조하고 있으며, 이는 글로벌 AI 및 데이터 분석 기업에 영향을 미치고 있어, 데이터 랭글링 시장에 심각한 우려를 불러일으키고 있습니다.
- 2025년 2월, COMPLY는 AI 기반 컴플라이언스 자동화 및 데이터 거버넌스를 강조하는 2025 혁신 로드맵을 발표했습니다. 새로운 Employee360 대시보드는 최고 컴플라이언스 책임자(CCO)에게 직원 위험 및 규제 의무에 대한 실시간 감독 기능을 제공합니다. 규제 복잡성이 증가함에 따라 이는 데이터 거버넌스 및 컴플라이언스 솔루션에 대한 수요 증가를 강조하며, 데이터 랭글링 시장에서 금융 서비스 기업의 규제 데이터 관리를 간소화하고, 정확성을 향상시키며, 컴플라이언스 프로세스를 자동화할 수 있는 중요한 기회를 제공합니다.
- 2024년 6월, 클라우데라는 고객의 데이터, 분석 및 AI 애플리케이션 개발 속도를 높이기 위해 세 가지 AI 기반 어시스턴트를 출시했습니다. 클라우데라 머신러닝용 클라우데라 코파일럿(Cloudera Copilot for Cloudera Machine Learning) 어시스턴트 중 하나는 사전 훈련된 LLM을 활용하여 데이터 준비 및 모델 배포와 같은 과제를 지원합니다.
SKU-
세계 최초의 시장 정보 클라우드 보고서에 온라인으로 접속하세요
- 대화형 데이터 분석 대시보드
- 높은 성장 잠재력 기회를 위한 회사 분석 대시보드
- 사용자 정의 및 질의를 위한 리서치 분석가 액세스
- 대화형 대시보드를 통한 경쟁자 분석
- 최신 뉴스, 업데이트 및 추세 분석
- 포괄적인 경쟁자 추적을 위한 벤치마크 분석의 힘 활용
연구 방법론
데이터 수집 및 기준 연도 분석은 대규모 샘플 크기의 데이터 수집 모듈을 사용하여 수행됩니다. 이 단계에는 다양한 소스와 전략을 통해 시장 정보 또는 관련 데이터를 얻는 것이 포함됩니다. 여기에는 과거에 수집한 모든 데이터를 미리 검토하고 계획하는 것이 포함됩니다. 또한 다양한 정보 소스에서 발견되는 정보 불일치를 검토하는 것도 포함됩니다. 시장 데이터는 시장 통계 및 일관된 모델을 사용하여 분석하고 추정합니다. 또한 시장 점유율 분석 및 주요 추세 분석은 시장 보고서의 주요 성공 요인입니다. 자세한 내용은 분석가에게 전화를 요청하거나 문의 사항을 드롭하세요.
DBMR 연구팀에서 사용하는 주요 연구 방법론은 데이터 마이닝, 시장에 대한 데이터 변수의 영향 분석 및 주요(산업 전문가) 검증을 포함하는 데이터 삼각 측량입니다. 데이터 모델에는 공급업체 포지셔닝 그리드, 시장 타임라인 분석, 시장 개요 및 가이드, 회사 포지셔닝 그리드, 특허 분석, 가격 분석, 회사 시장 점유율 분석, 측정 기준, 글로벌 대 지역 및 공급업체 점유율 분석이 포함됩니다. 연구 방법론에 대해 자세히 알아보려면 문의를 통해 업계 전문가에게 문의하세요.
사용자 정의 가능
Data Bridge Market Research는 고급 형성 연구 분야의 선두 주자입니다. 저희는 기존 및 신규 고객에게 목표에 맞는 데이터와 분석을 제공하는 데 자부심을 느낍니다. 보고서는 추가 국가에 대한 시장 이해(국가 목록 요청), 임상 시험 결과 데이터, 문헌 검토, 재생 시장 및 제품 기반 분석을 포함하도록 사용자 정의할 수 있습니다. 기술 기반 분석에서 시장 포트폴리오 전략에 이르기까지 타겟 경쟁업체의 시장 분석을 분석할 수 있습니다. 귀하가 원하는 형식과 데이터 스타일로 필요한 만큼 많은 경쟁자를 추가할 수 있습니다. 저희 분석가 팀은 또한 원시 엑셀 파일 피벗 테이블(팩트북)로 데이터를 제공하거나 보고서에서 사용 가능한 데이터 세트에서 프레젠테이션을 만드는 데 도움을 줄 수 있습니다.